Editing Files at 1000 Tokens per Second
Frontier models such as GPT-4o struggle on large edits, with problems of laziness, inaccuracy, and high-latency.
This is a weakness visible in coding agents. Accurately editing hundreds of lines can take multiple model calls, at times trapping the agent in an infinite loop. Even small, isolated edits are plagued with bugs.
Worst of all, existing models are slow at large edits, breaking the programmer out of flow.
We've trained a specialized model on an important version of the full-file code edit task called fast apply.
Difficult code edits can be broken down into two stages: planning, and applying.
In Cursor, the planning phase takes the form of a chat interface with a powerful frontier model. Applying the change to the current file should be straightforward and instant.
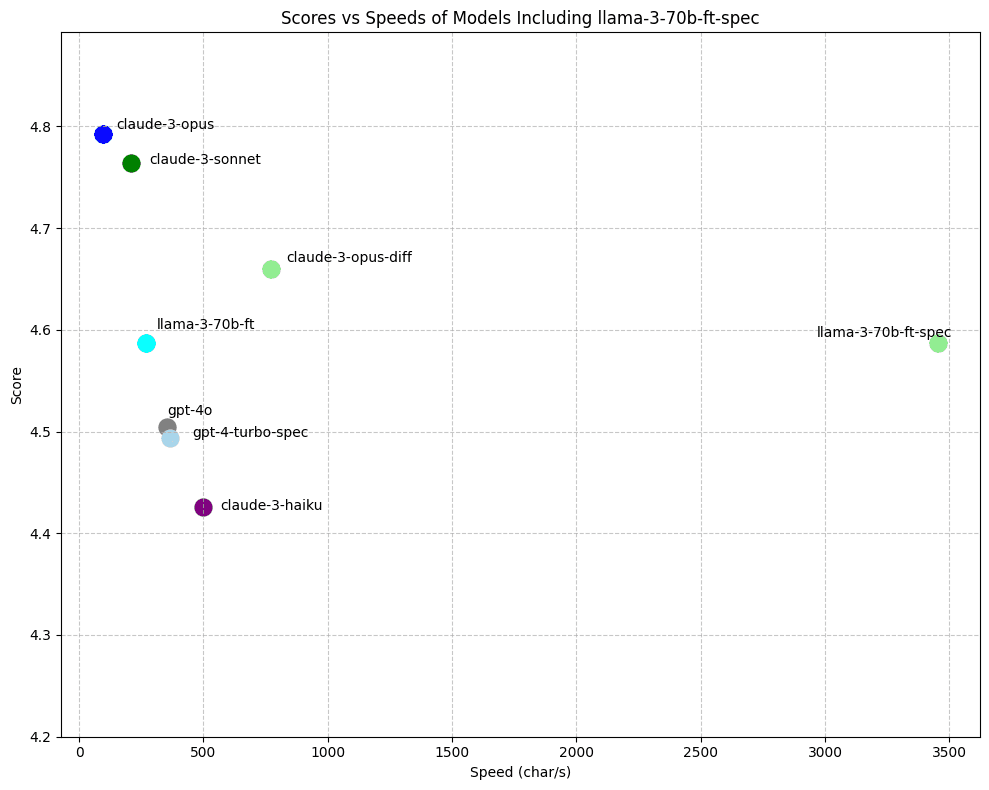
Our fast-apply model surpasses GPT-4 and GPT-4o performance and pushes the pareto frontier on the accuracy / latency curve. We achieve speeds of ~1000 tokens** (around 3500 char/s) on our 70b model using a speculative-decoding variant tailored for code-edits, called speculative edits.
This means a ~13x speedup over vanilla inference using Llama-3-70b and a ~9x speedup over our previous GPT-4 speculative edits deployment.
By default, we have language models generate the fully rewritten file conditioned on the current file, the conversation history, and the current code block.
In this post, we explain how we trained and evaluated our new model. We show why we rewrite the file instead of using diffs and how speculative edits give us such ridiculous speedups.
Evaluating Prompted Rewrites
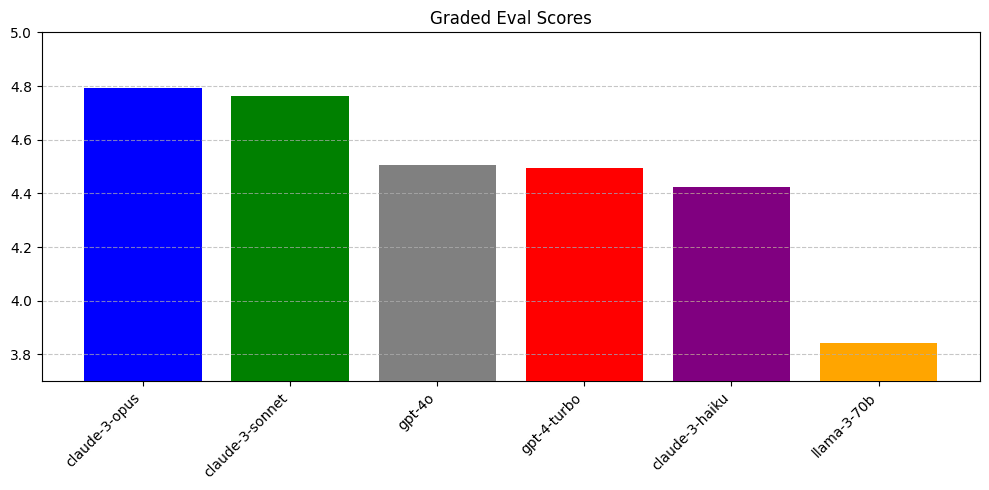
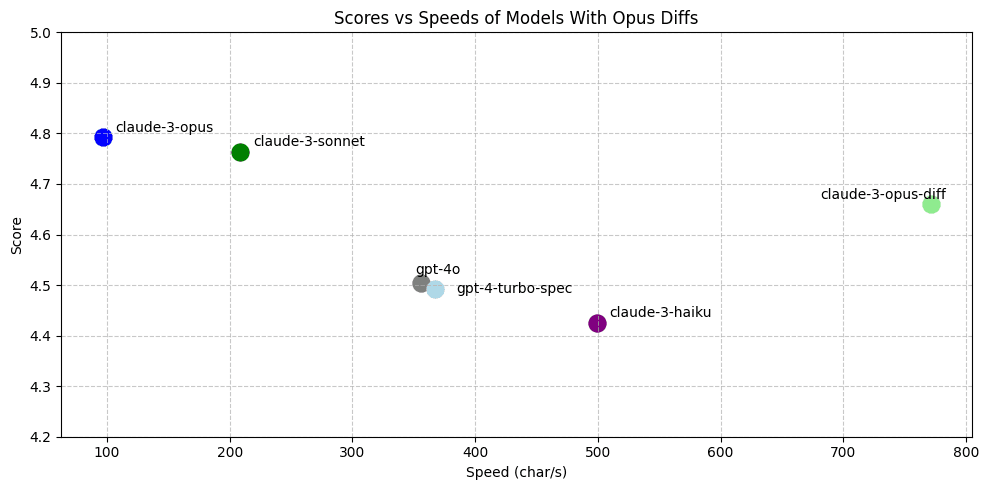
We construct an evaluation set of ~450 full-file edits of files under 400 lines, then measure the performance of several prompted models using Claude-3 Opus as a grader.
Across tens of curated examples, Opus-based grading shows more agreement with our ratings than GPT-4-Turbo or GPT-4o.
These scores likely bias towards outputs of Claude models. But the scores also match our qualitative assessments of the models.
We hypothesize Claude's superior performance is an artifact of post-training.
The claude models output thousands of LOC in assistant messages, while GPT-4 omits code and indicates missing regions with ... or comments.
GPT-4's poor performance can also be attributed to unrelated changes. GPT-4 deletes commented out code and unnecessary newlines. It has a tendency to "fix/clean up" unrelated code.
Speed Measurements
We measure speed as:
This has the advantages of:
-
Normalizes speed across different tokenizers
-
Presents a single number we care about across various prompt/generated token lengths (vs counting both TTFT and generation char/s)
-
Gives a strong lower-bound on generation-speed since the latency includes TTFT. For most tokenizers and text, a token is 3-4 characters, so dividing char/s by 4 gives a tokens/s lower bound.
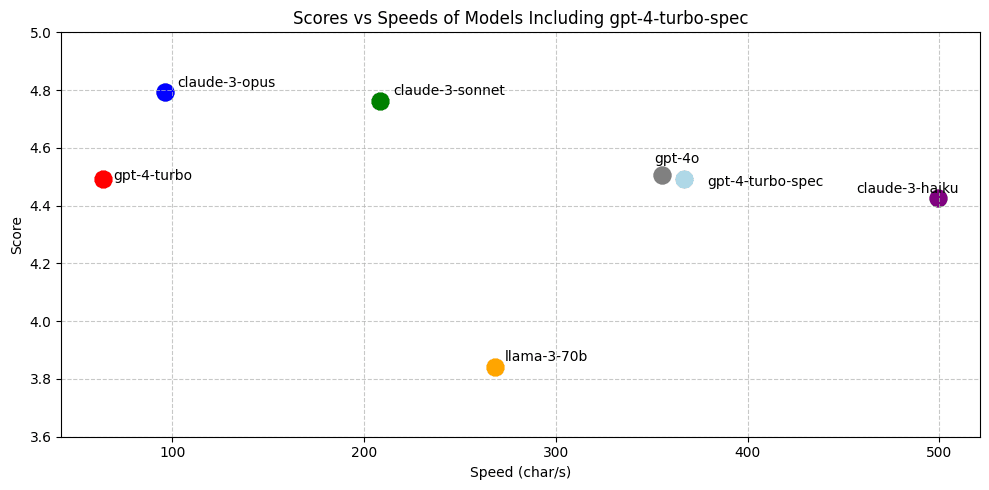
When we include speedups from gpt-4-turbo speculative edits:
Diff Models
Why do we have the model rewrite the entire file, instead of suggesting diffs?
We found that language models struggle with diff-formatted edits for a few possible reasons:
Thinking in Fewer Tokens - With more output tokens, the model has more forward passes to determine the correct solution. Diffs force the model to think in fewer tokens.
Diffs are Out of Distribution - In pretraining and especially post-training, models have likely seen more full-files of code than diffs of code.
Outputting Line Numbers - If a tokenizer treats a sequence of numbers (i.e. 123) as a single token, it must make up its mind about the correct line number for the diff on a single (often the first) output token. Furthermore, models are notoriously bad at counting line numbers.
Motivated by the diff format from Aider, we eliminate the line number problem. Instead of a standard diff format, the model proposes diff hunks as search/replace blocks:
diff
@@ ... @@
function binarySearch(arr, x) {
- let low = 0, high = arr.length - 1;
- while (low <= high) {
- let mid = Math.floor((low + high) / 2);
- if (arr[mid] === x) {
- return mid;
- }
- low += 1;
- }
- return -1;
+ let low = 0, high = arr.length - 1;
+ while (low <= high) {
+ let mid = Math.floor((low + high) / 2);
+ if (arr[mid] === x) {
+ return mid;
+ } else if (arr[mid] < x) {
+ low = mid + 1;
+ } else {
+ high = mid - 1;
+ }
+ }
+ return -1;
}
We replace all lines starting with - or with lines starting with + or .
The diffs have redundant -s and + s so the diff-parsing system is robust to minor model failures.
Most models fail to output accurate diffs, with the exception of Claude Opus.
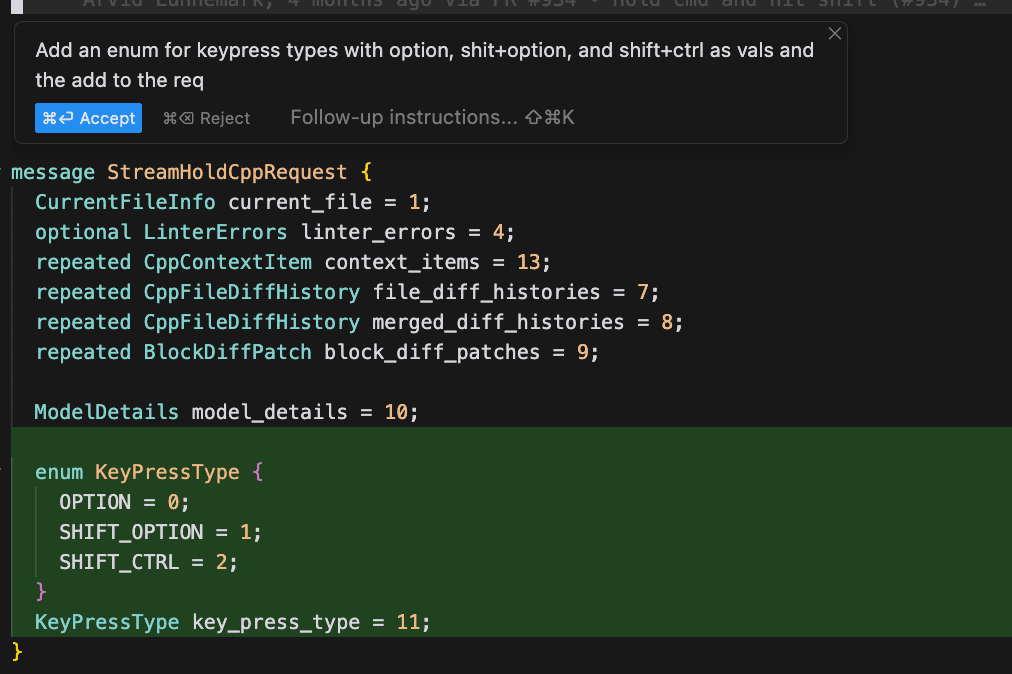
Training
The claude-3-opus-diff apply model is faster and more accurate than gpt-4-turbo-spec, but is still too slow.
It is not possible to build speculative edits into any of anthropic's models, so we need to train and deploy a performant custom model.
Synthetic Data
We begin with a small number of "fast-apply" prompts and an abundance of cmd-k prompts.
A cmd-k prompt loosely resembles the data we need for fast-apply. It contains an edit instruction, and a code selection in the current file.
For each edit instruction, we have GPT-4 produce a chat response given the current file, then have a language model "apply" the change. We use the small dataset of "real" apply inputs to produce additional higher-quality apply datapoints. Finally, we concatenate these datasets together in an 80/20 mix to get our finetuning data.
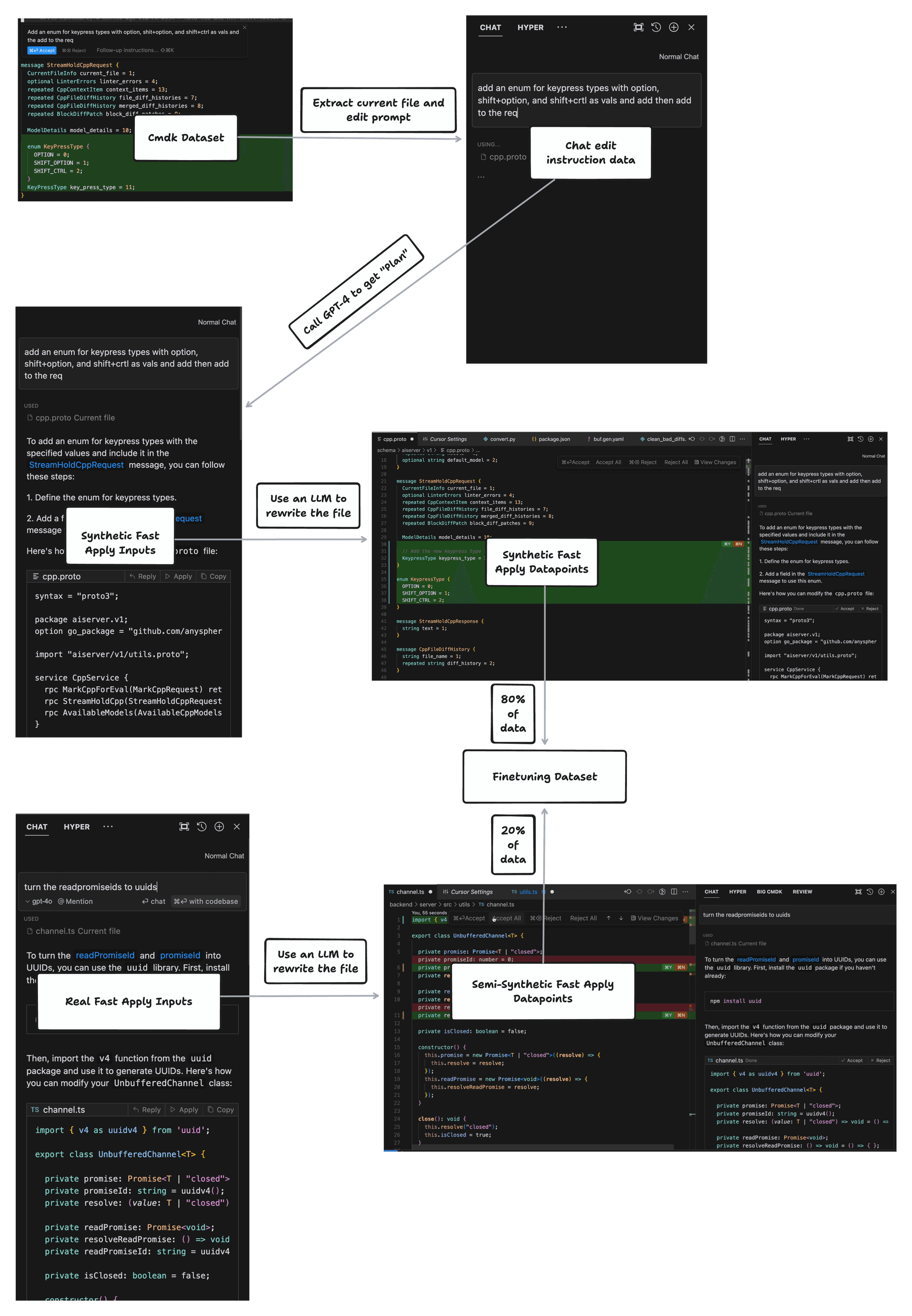
Model Training
We train the Deepseek Coder Instruct and Llama 3 model families. To improve our finetuning dataset, we:
-
We downsample small files since they were over-represented in our train set (<100 LOC).
-
We downsample the number of training examples per filename.
-
We downsample datapoints that resulted in no-ops.
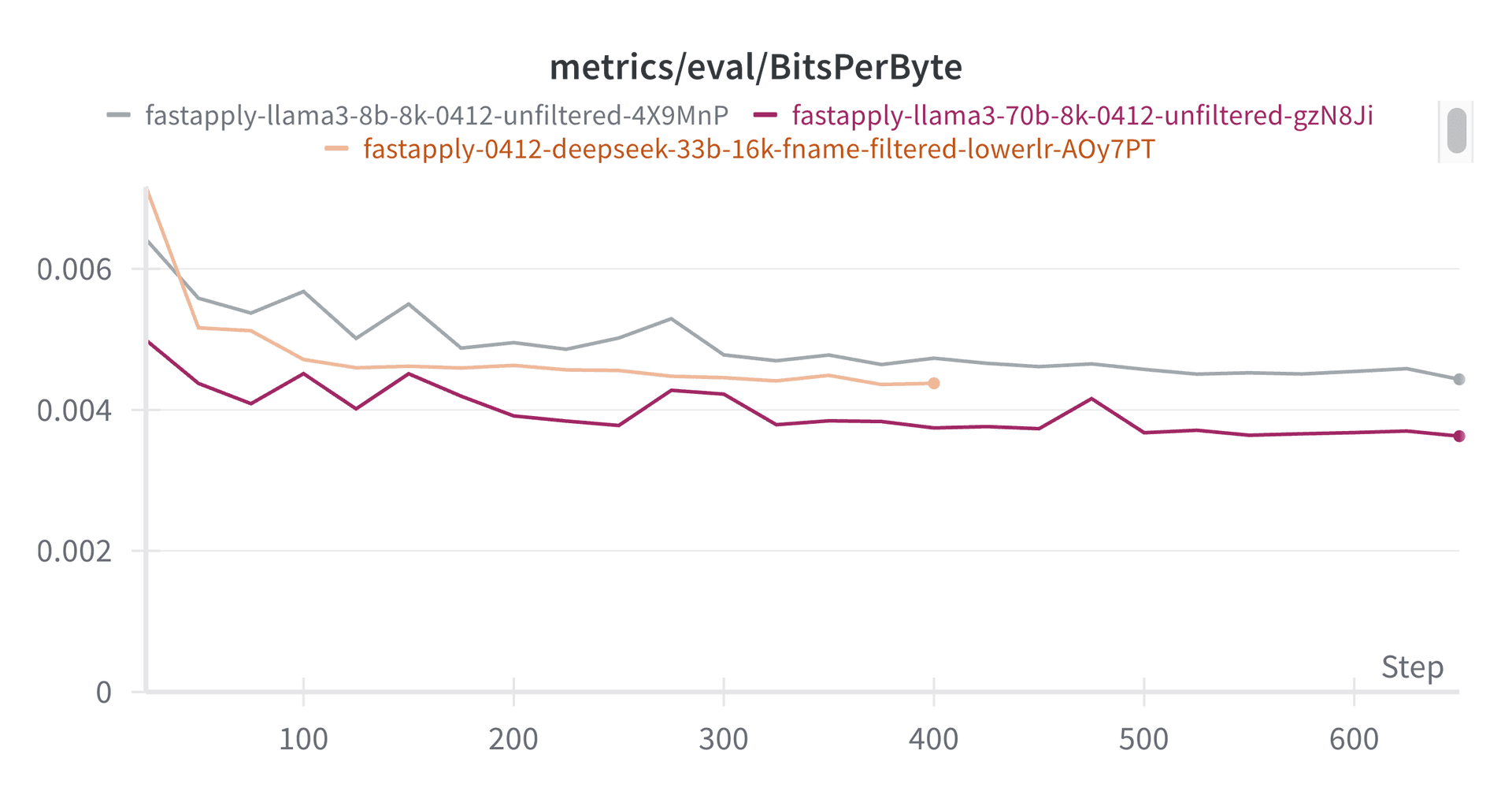
We find that our best model (llama-3-70b-ft) almost matches claude-3-opus-diff and outperforms gpt-4-turbo and gpt-4o.
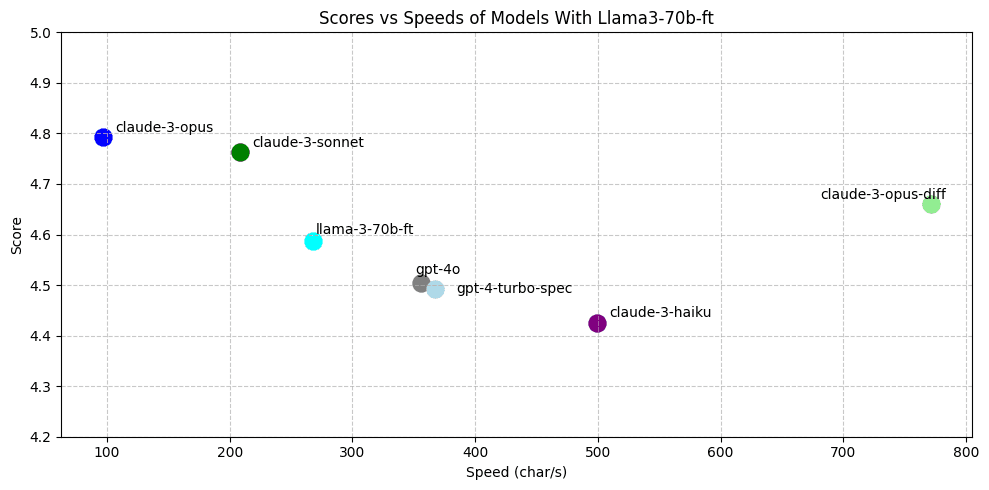
All three finetuned models outperform gpt-4-turbo on evals, but we could feel the difference between the finetuned deepseek-33b and llama-3-70b. Llama-3-70b felt better than other finetuned models and gpt-4-turbo. The other finetuned models felt not-quite-useful enough, often less useful than GPT-4.
Speculative edits
Our biggest win comes from our custom speculative decoding algorithm called "speculative edits". It is equivalent to a full-file-rewrite, while being up to 9x faster.
With code edits, we have a strong prior on the draft tokens at any point in time, so we can speculate on future tokens using a deterministic algorithm rather than a draft model.
We've worked with Fireworks to deploy our fast-apply model with strong speculative edits support. They have a fantastic inference engine and built out api support for our custom speculation logic.
This makes the gain from speculative edits larger for Llama-3 than GPT-4, meaning a 4-5x speedup over the next fastest model.
Future Directions
Long Context Training - We are working on long-context training to rewrite files up to 2500 lines long. Naive linear scaling of RoPE position ids works poorly -- as do current community long-context finetunes of Llama 3 70b.
Knowledge Distillation - We'also like to distill the "fast apply" abilities of the current model into a smaller one, particularly llama-3-8b. The lower latencies from smaller models will matter more for larger files.
Even Better Accuracy - Some form of on-policy RL using data from the newly rolled-out model should give us additional performance wins.
Past its usefulness in chat, fast-apply is crucial building block for more sophisticated code-generation systems. As models get more capable at reasoning/planning, there are increasing benefits to a low-latency apply!
If you haven't already, you should try out this feature in Cursor! It's a small example of the polish and depth that goes into the product.
This blog post is a reasonable sample of the applied research we do at Cursor. We build application-specific inference speedups like speculative edits, train and evaluate task-specific models, and ship these in useful features to users.
We're hiring research engineers and software engineers! You can learn more at cursor.com/careers.