智能体用量提升
1 分钟阅读
我们提高了所有个人方案中 Auto 和 Composer 1.5 的用量上限。
现在有两个用量池:
- 第一方模型用量池: 发布时,我们为 Auto 和 Composer 1.5 提供了显著更多的用量。
- API: 我们按模型的 API 价格收费 (本次更新未作调整) 。
Composer 1.5 现在拥有 Composer 1 的 3 倍用量上限。在限时期间内 (截至 2 月 16 日) ,我们会将该上限进一步提高到 6 倍。
从自动补全到智能体
在过去几个月里,我们明显看到开发方式正在向依赖智能体的模式转变。
开发者开始让 Cursor 在整个代码库中进行大规模、雄心勃勃的修改。我们希望 Cursor 能够支持开发者的日常“智能体编程”工作方式,同时也意识到不同开发者有着不同的侧重点。
有些人愿意始终为最新的模型买单,而另一些人则更看重速度、智能和成本之间的最佳平衡。通过引入两个用量池并提升第一方模型的配额,我们正在同时满足这两种需求。
面向智能代理编程的新模型
通过自研模型(如 Composer-1.5),我们能够以更可持续的方式提供显著更高的使用量。
我们发现 Composer 1.5 能力非常强,在 Terminal-Bench 2.0 上的得分高于 Sonnet 4.5,但仍低于当前最顶级的前沿模型。1


我们预计会持续探索新的方式,在提供最新前沿模型的同时,推出更智能、更具性价比的模型。
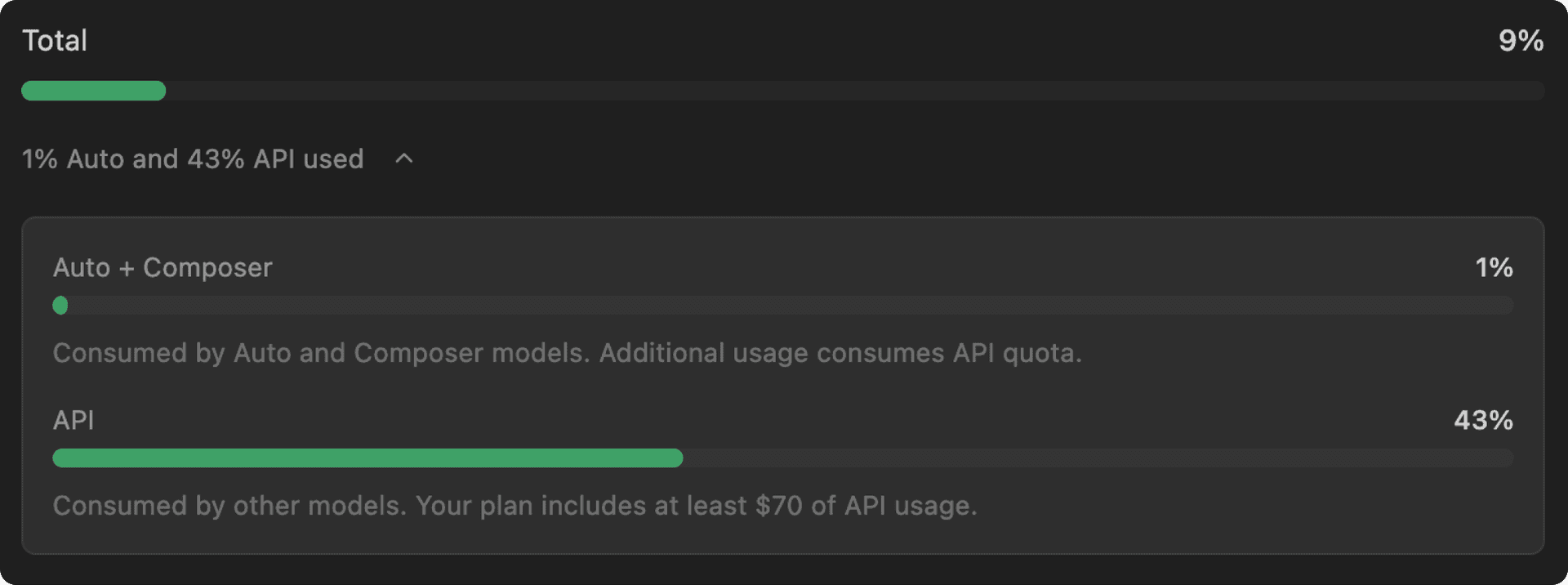
使用情况可见性改进
为了进一步提升对使用情况的可见性,我们在编辑器中新增了一个页面,你可以在其中通过两个不同的用量池来监控各自的使用上限:
- 第一方模型使用池: 在发布时,当选择 “Auto” 或
composer-1.5时,我们提供了显著更多的使用配额。 - API: 个人方案每月至少包含价值 20 美元的使用量 (更高档位包含更多) ,并且可以按需额外付费购买使用量。本次更新没有更改这些使用上限。

试用我们的最新模型
我们鼓励你在更新后的用量额度下试用 Composer 1.5。
这两个用量池都会在你的每月计费周期中重置。这些额度现已适用于所有个人套餐(Pro、Pro Plus 和 Ultra)。
- Terminal-Bench 2.0 是由 Laude Institute 维护的、用于终端环境的智能体评测基准。Anthropic 模型分数使用 Claude Code harness,OpenAI 模型分数使用 Simple Codex harness。我们的 Cursor 分数是使用官方的 Harbor evaluation framework(Terminal-Bench 2.0 指定的 harness),在默认基准设置下计算得出。每个模型与智能体组合我们运行了 2 次迭代,并报告其平均值。有关该基准的更多详细信息,请参见官方的 Terminal Bench 网站。对于除 Composer 1.5 以外的其他模型,我们在 官方排行榜 分数与在我们基础设施中运行记录的分数之间,取最高值作为最终得分。↩