提高代理使用額度
閱讀時間 1 分鐘
我們已針對所有個人方案提高 Auto 與 Composer 1.5 的使用額度限制。
現在有兩種使用額度池:
- 第一方模型用量池: 在推出時,我們為 Auto 和 Composer 1.5 提供顯著更多的用量。
- API: 我們依照模型的 API 價格收費 (本次更新未變更) 。
Composer 1.5 現在擁有 Composer 1 三倍的使用額度限制。在限時期間內 (至 2 月 16 日) ,我們會將該使用額度限制進一步提高到 6 倍。
從自動補全到代理
在過去幾個月中,我們看到程式開發正大幅轉向透過代理來編寫程式碼。
開發者開始要求 Cursor 對整個程式碼庫進行大膽而重大的變更。我們希望 Cursor 能支援日常的代理式程式開發,同時也理解開發者有不同的優先考量。
有些人樂於隨時為最新的模型付費,而另一些人則在尋找速度、智慧程度與成本之間的最佳平衡。透過引入兩種使用額度池並提升第一方模型的使用額度限制,我們同時支援這兩種模式。
用於代理式程式開發的新模型
透過訓練我們自家的模型(例如 Composer 1.5),我們可以以可持續的方式提供明顯更多的使用額度。
我們發現 Composer 1.5 是一個能力非常強大的模型,在 Terminal-Bench 2.0 上的得分高於 Sonnet 4.5,但仍低於最頂尖的前沿模型。1


我們預計會持續探索更多方法,在提供最新前沿模型的同時,推出越來越智慧且具成本效益的模型。
改善使用狀況透明度
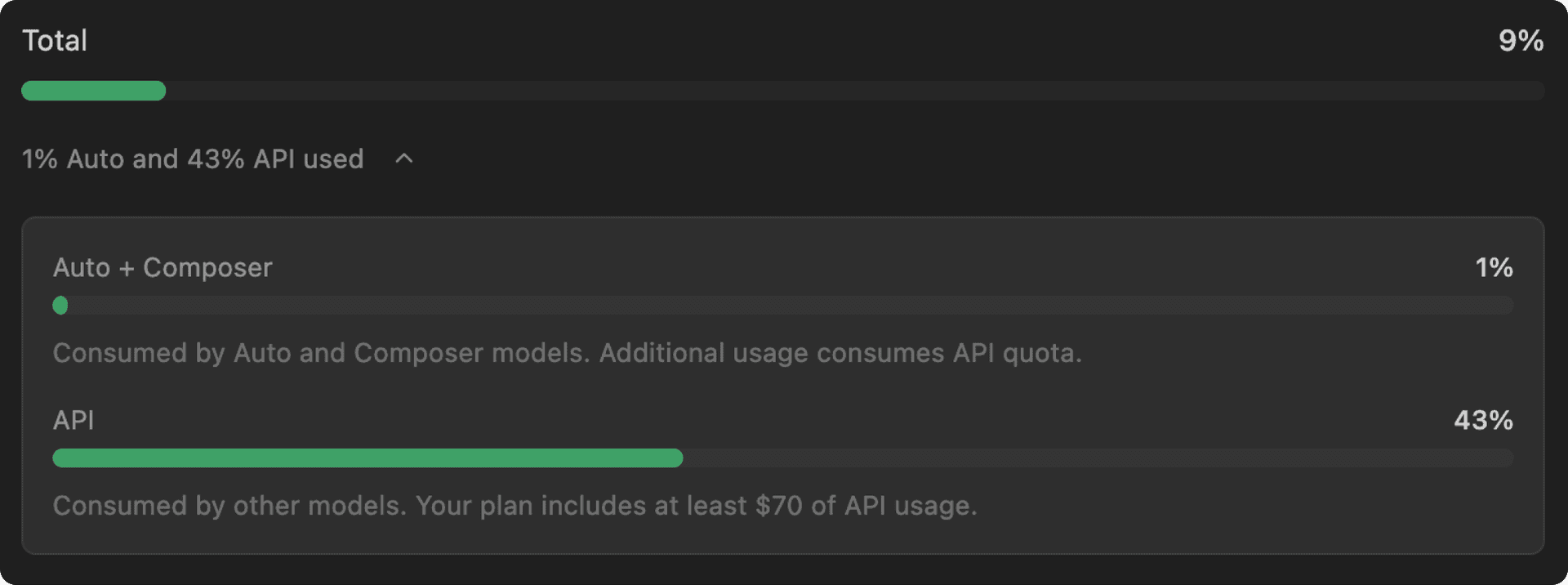
為了進一步提升使用狀況的透明度,我們在編輯器中新增了一個頁面,讓你可以透過兩個不同的使用額度池來監控你的使用額度限制:
- 第一方模型用量池: 在推出時,當選擇「Auto」或
composer-1.5時,我們會提供顯著更多的用量。 - API: 個人方案每個月都會獲得至少價值 20 美元 (更高階方案則會更多) 的內含使用額度,並可視需要額外付費購買使用量。這次更新並未變更使用額度限制。

試用我們最新的模型
我們鼓勵你試用 Composer 1.5,並體驗我們更新後的使用額度限制。
兩個使用額度池都會在你的每月計費週期中重置。這些限制現在已套用到所有個人方案(Pro、Pro Plus 和 Ultra)。
- Terminal-Bench 2.0 是由 Laude Institute 維護、用於終端機使用情境的代理(agent)評估基準測試。Anthropic 模型得分是透過 Claude Code 測試工具取得,而 OpenAI 模型得分則是透過 Simple Codex 測試工具取得。我們的 Cursor 得分是使用官方的 Harbor 評估框架(Terminal-Bench 2.0 指定的測試工具),在預設基準設定下計算而得。我們針對每個模型與代理配對執行 2 次測試,並取其平均值。可在官方的 Terminal-Bench 網站 了解更多關於該基準測試的細節。對於 Composer 1.5 之外的其他模型,我們取 官方排行榜 得分與在我們基礎架構上執行所得得分兩者中的較高者。↩