Cursor에서 모델 품질을 비교하는 방법
참고: CursorBench는 에이전트 기능이 발전함에 따라 지속적으로 업데이트됩니다. 현재 프로덕션 버전은 CursorBench 3.1이며, 최신 리더보드는 해당 페이지에서 확인하세요.
개발자들은 이제 코딩 에이전트에게 여러 파일, 도구, 단계에 걸친 더 길고 복잡한 작업을 맡기고 있습니다. 이런 요청의 범위가 커질수록 에이전트 성능을 측정하는 eval도 그에 맞게 진화해야 합니다.
Cursor에서는 개발자가 실제로 하는 작업에 맞춰 모델 품질에 대한 이해를 유지하기 위해 하이브리드 온라인-오프라인 eval 프로세스를 사용합니다.
오프라인 부분은 엔지니어링 팀의 실제 Cursor 세션을 바탕으로 구축한 내부 eval 스위트인 CursorBench를 사용합니다. 작업이 공개 저장소가 아니라 실제 Cursor 사용에서 나오기 때문에, CursorBench는 공개 벤치마크보다 모델 간 차이를 더 잘 구분하고 실제 개발자 성과와도 더 잘 맞습니다.
CursorBench는 정답 정확성, 코드 품질, 효율성, 상호작용 방식 등 에이전트 성능의 여러 차원을 측정하도록 설계되었습니다. 이 블로그에서는 정답 정확성 결과에 초점을 맞추지만, 실제로는 이 모든 축에서 에이전트를 eval합니다.
업데이트, 2026년 5월: 이후 더 어려운 과제를 포함해 CursorBench를 3.1로 업데이트했습니다. 과제 분포가 바뀌었기 때문에 CursorBench 3.1 점수는 이 게시물의 수치 및 차트와 차이가 있을 수 있으며, 동일한 eval version 내에서 비교해야 합니다.


또한 CursorBench를 라이브 트래픽에 대한 통제된 분석으로 보완합니다. 이러한 온라인 eval은 오프라인 스위트가 놓치는 회귀를 잡아내는데, 예를 들어 에이전트 출력이 평가기에는 올바르게 보여도 실제 제품을 사용하는 개발자에게는 더 나쁘게 느껴지는 경우가 있습니다.
이 온라인-오프라인 루프를 함께 사용하면 워크플로가 바뀌어도 모델 품질에 대한 기준을 실제 프로덕션에 맞게 유지할 수 있고, Cursor에서 가능한 최상의 에이전트 경험을 만들어갈 수 있습니다.
공개 벤치마크의 한계
좋은 벤치마크는 실제 사용 환경에서 성능 차이가 나는 모델을 구분할 수 있어야 하고, 동시에 개발자가 그 모델을 실제로 경험하는 방식과도 맞아야 합니다. 하지만 공개 오프라인 평가는 이 두 가지 모두에서 한계를 보입니다.
첫 번째 문제는 정렬입니다. 개발자들이 에이전트와 함께 점점 더 복잡하고 다양한 작업을 하게 되면서, 정적인 벤치마크나 실제 사용과 어긋난 벤치마크는 결국 완전히 엉뚱한 것을 평가하게 됩니다. 예를 들어 대부분의 SWE 벤치마크는 여전히 버그 수정 작업에 초점을 맞추고 있습니다. 마찬가지로 Terminal-Bench는 특정 체스판 위치에서 최선의 수를 찾아내는 것처럼, 폭넓은 퍼즐형 과제를 강조합니다. 저희는 이런 과제들이 개발자들이 에이전트에게 요청하는 코딩 작업과는 잘 맞지 않는다고 봅니다.
두 번째는 채점입니다. 많은 공개 벤치마크 과제는 정답이 되는 해법의 범위가 좁다고 가정하지만, 대부분의 개발자 요청은 여러 가지 타당한 접근 방식을 허용할 만큼 명세가 충분히 구체적이지 않습니다. 그 결과 벤치마크는 올바른 대안적 접근 방식을 불이익 주거나, 이런 명세 부족을 없애기 위해 인위적인 요구 사항을 덧붙이게 됩니다. 어느 쪽도 실제 성능을 정확하게 평가하지 못합니다.
세 번째는 오염입니다. SWE-bench Verified, Pro, Multilingual은 모두 공개 저장소에서 과제를 가져오는데, 이런 과제들이 결국 모델 학습 데이터에 포함되어 점수를 부풀리게 됩니다. OpenAI는 최근 최전선 모델이 정답 패치를 기억만으로 재현할 수 있고, 아직 해결되지 않은 문제의 거의 60%에 결함 있는 테스트가 있다는 사실을 확인한 뒤 SWE-bench Verified 결과 보고를 완전히 중단했습니다.
그 결과, 최전선 수준에서는 이러한 벤치마크가 개발자에게 제공하는 효용이 매우 다른 모델들을 더 이상 구분해 내지 못합니다.
CursorBench 구축하기
저희는 커밋된 코드를 이를 생성한 에이전트 요청까지 추적하는 Cursor Blame을 사용해 CursorBench용 작업을 수집합니다. 이를 통해 개발자 질의와 정답 역할을 하는 해결책이 자연스럽게 짝지어집니다. 많은 작업이 저희 내부 코드베이스와 통제된 소스에서 나오기 때문에, 모델이 학습 과정에서 이를 접했을 가능성을 줄일 수 있습니다. 또한 개발자들이 에이전트를 사용하는 방식의 변화를 추적하기 위해 몇 달마다 벤치마크 구성을 갱신합니다.
정확성 평가에서 다루는 문제 범위는 초기 버전에서 현재 버전인 CursorBench-3까지, 코드 줄 수와 평균 파일 수 기준 모두에서 대략 두 배로 늘었습니다. CursorBench-3 작업은 SWE-bench Verified, Pro, Multilingual의 작업보다 훨씬 더 많은 코드 줄 수를 포함합니다. 코드 줄 수는 난이도를 재는 완벽한 척도는 아니지만, 이 지표의 증가는 모노레포 기반의 멀티 워크스페이스 환경 처리, 프로덕션 로그 조사, 장시간 실행되는 실험 수행 같은 더 어려운 작업들을 CursorBench에 반영해 왔음을 보여줍니다.
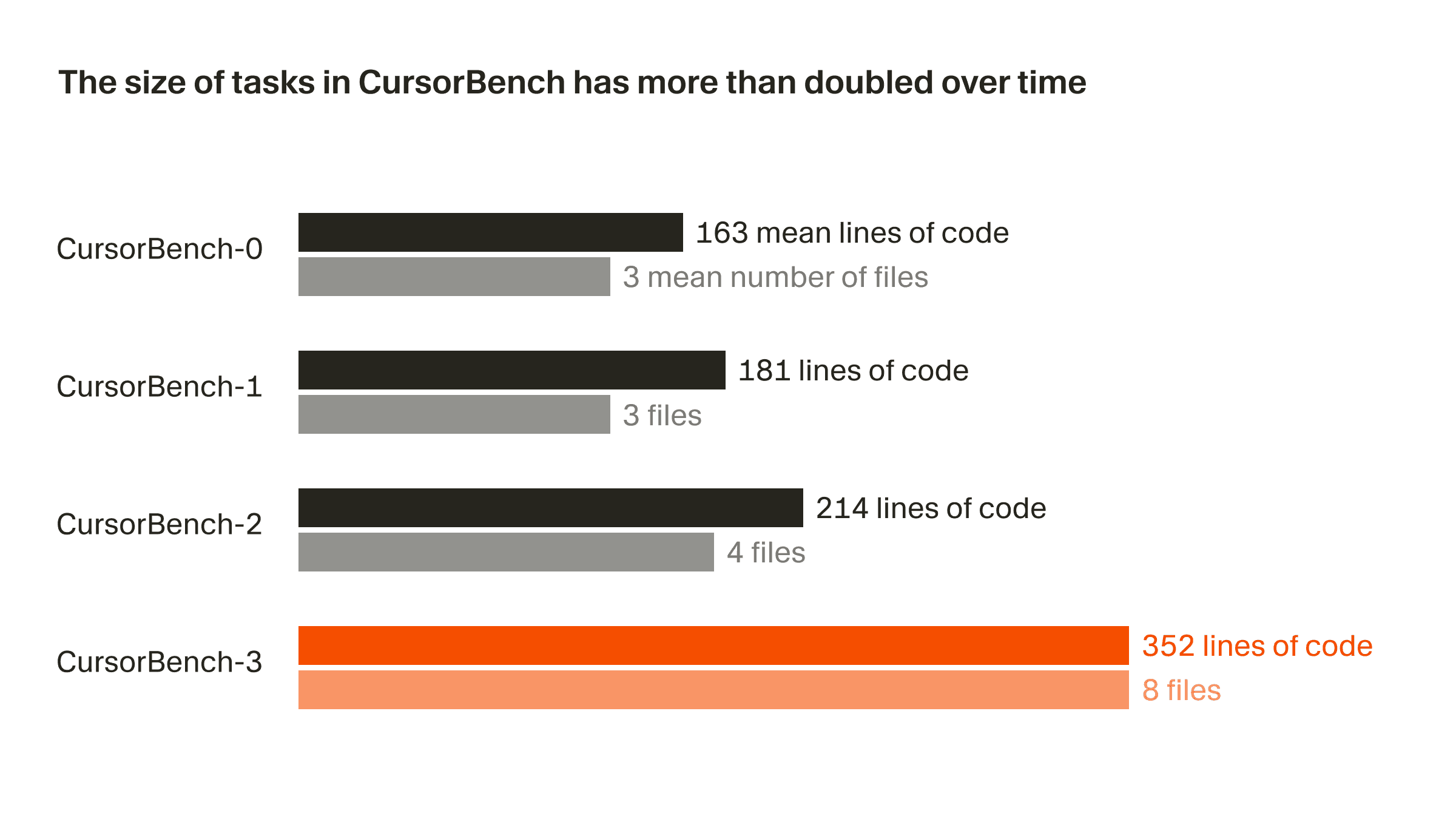
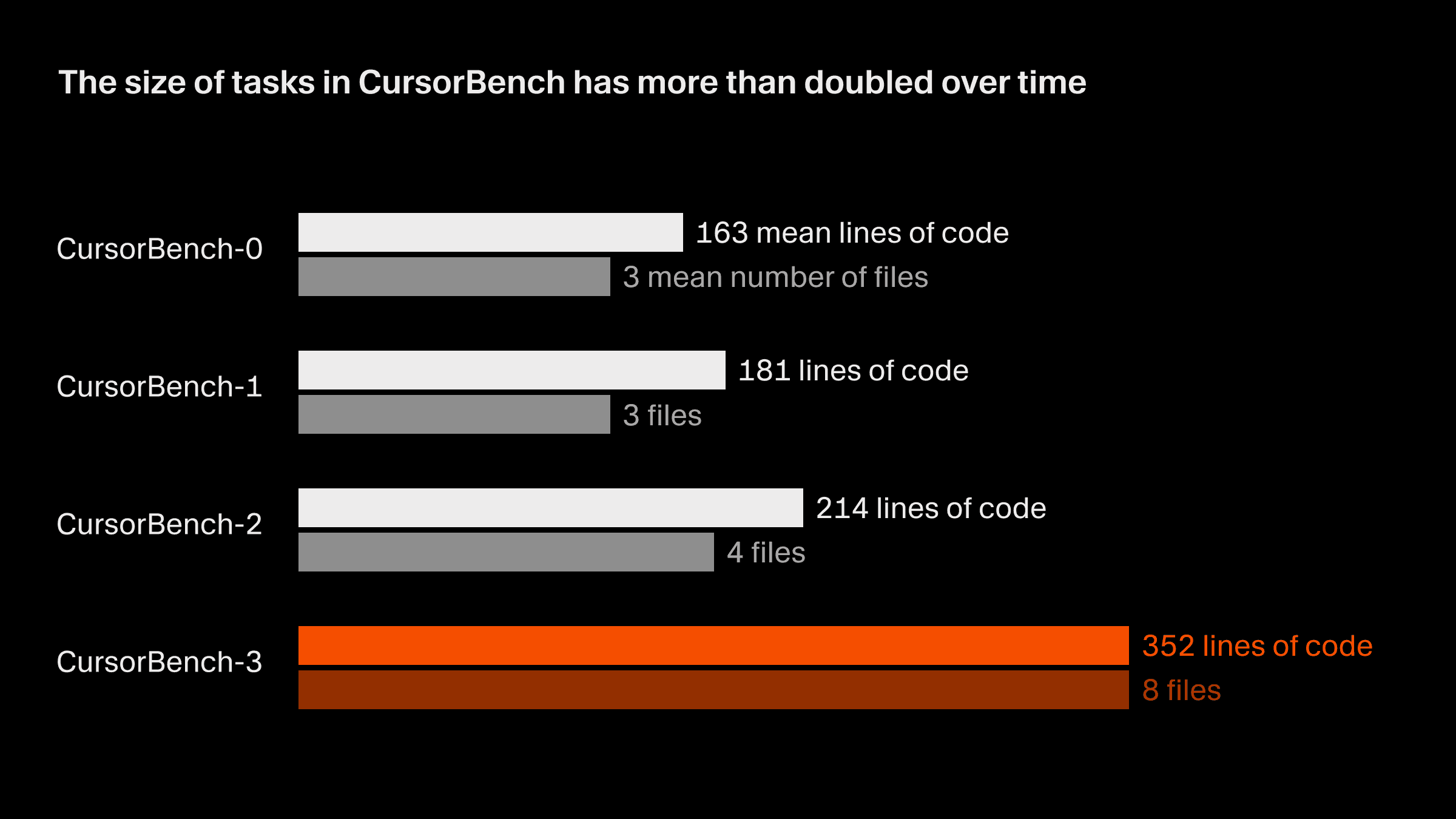
CursorBench 작업은 개발자들이 에이전트와 소통하는, 구체적이지 않고 종종 모호한 방식과도 잘 맞습니다. 공개 벤치마크가 GitHub 이슈에서 가져온 상세한 설명을 사용하는 것과 달리, 저희 작업 설명은 의도적으로 짧으며 이를 안정적으로 채점하기 위해 에이전트형 채점기를 사용합니다.


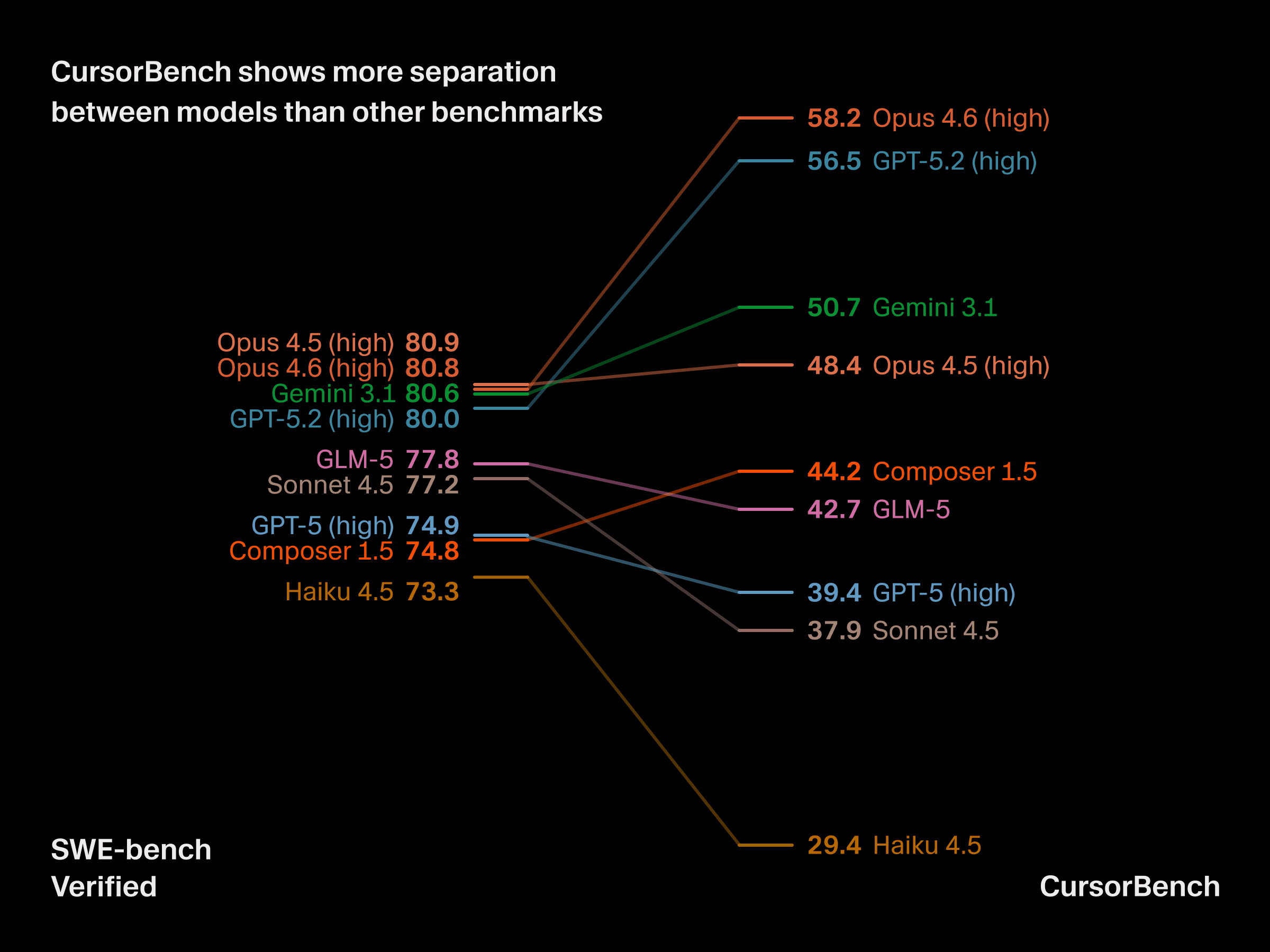
CursorBench는 모델 간 격차를 더 뚜렷하게 보여줍니다
작업 복잡도와 명세의 이러한 차이는 벤치마크의 실질적인 유용성에 실제적인 영향을 미칩니다. CursorBench는 공개 벤치마크가 점점 포화되고 있는 프런티어 수준에서 모델 간 격차를 더 뚜렷하게 보여주며, 경우에 따라 Haiku 같은 모델이 GPT-5와 맞먹거나 이를 능가하기도 합니다. CursorBench는 개발자들이 체감상 의미 있게 다르다고 느끼는 모델들을 안정적으로 구분해 냅니다.

CursorBench 점수는 온라인 평가 결과와 부합합니다
온라인 평가는 에이전트에 대한 개선이 실제로 개발자에게 도움이 되는지를 측정합니다. 저희는 상호작용과 출력 품질 신호를 모두 포함해 에이전트 성과를 보여주는 여러 상위 수준 지표를 추적하며, 단일 지표만 최적화하기보다 이들 전반에서 일관된 변화가 나타나는지 확인합니다. 이를 종합하면 에이전트 출력이 오프라인 평가기에서는 높은 점수를 받더라도, 실제로는 개발자에게 잘 작동하지 않는 회귀를 잡아낼 수 있습니다.
저희는 영향을 정확히 파악하기 위해 통제된 온라인 실험을 사용합니다. 예를 들어 의미 기반 검색 및 검색 결과 가져오기를 개선하는 과정에서, 의미 기반 검색 도구를 완전히 제거하는 제거 실험을 진행했습니다. 이를 통해 대규모 코드베이스에서의 저장소 기반 질의응답처럼 의미 기반 검색이 특히 중요한 시나리오를 정확히 찾아낼 수 있었습니다.
CursorBench 순위는 저희의 온라인 평가 지표로 측정한, 개발자가 Cursor에서 체감하는 모델 품질과도 더 밀접하게 일치합니다.


다음 eval 스위트
CursorBench-3의 작업은 공개 벤치마크의 작업보다 더 길지만, 여전히 하나의 세션 안에서 완료됩니다. 앞으로 1년 안에 개발 작업의 대부분이 각자의 컴퓨터에서 스스로 작업하는 장시간 실행 에이전트로 옮겨갈 것으로 보고 있으며, 이에 맞춰 CursorBench도 조정할 계획입니다. 이를 위해서는 채점 비용을 더 낮출 방법을 찾아내고, 외부 서비스와 상호작용하는 작업의 재현성 문제를 해결하며, 오프라인 평가와 실제 개발자 경험 사이의 격차를 줄여야 합니다.
온라인-오프라인 루프는 저희가 보기에 올바른 기반을 제공하며, 이를 바탕으로 발전시켜 나가면서 더 많은 내용을 공유할 계획입니다.
코딩의 미래와 관련된 깊이 있는 기술 문제를 함께 풀어가는 일에 관심이 있다면 hiring@cursor.com으로 연락해 주세요.