Iterieren mit Shadow Workspaces
Hier ist ein Rezept für Misserfolg: Füge ein paar relevante Dateien in ein Google Doc ein, schick den Link an deinen Lieblings-p60-Software-Engineer, der nichts über deine Codebasis weiß, und bitte ihn, deinen nächsten PR vollständig und korrekt direkt im Doc zu implementieren.
Bittest du eine KI um dasselbe, wird sie erwartungsgemäß ebenfalls scheitern.
Gib ihr stattdessen Remote-Zugriff auf deine Entwicklungsumgebung, mit der Möglichkeit, Lints zu sehen, zu Definitionen zu springen und Code auszuführen, und du kannst tatsächlich erwarten, dass sie dir zumindest ein Stück weit hilft.
Wir sind überzeugt, dass eine der Fähigkeiten, die es KIs ermöglichen wird, mehr von deinem Code zu schreiben, die Möglichkeit ist, direkt in deiner Entwicklungsumgebung zu iterieren. Lässt du KIs jedoch naiv in deinem Projektordner frei laufen, endet das im Chaos: Stell dir vor, du schreibst gerade eine komplexe, denkintensive Funktion, nur damit eine KI sie überschreibt, oder du versuchst, dein Programm auszuführen, während eine KI Code eingefügt hat, der nicht kompiliert. Um wirklich hilfreich zu sein, muss die KI-Iteration im Hintergrund stattfinden, ohne deine Arbeit im Editor zu stören.
Um das zu erreichen, haben wir in Cursor das implementiert, was wir den Shadow Workspace nennen. In diesem Blogpost skizziere ich zunächst unsere Designkriterien und beschreibe dann die Implementierung, die zum Zeitpunkt des Schreibens in Cursor existiert (ein verstecktes Electron-Fenster), sowie wohin wir sie in Zukunft entwickeln wollen (ein Kernel-Level-Ordner-Proxy).

Designkriterien
Wir möchten, dass der Shadow-Workspace die folgenden Ziele erreicht:
-
LSP-Nutzbarkeit: Die KIs sollten Lint-Warnungen aus ihren Änderungen sehen, zu Definitionen springen können und allgemein mit allen Teilen des Language Server Protocol (LSP) interagieren können.
-
Ausführbarkeit: Die KIs sollten ihren Code ausführen und die Ausgabe sehen können.
Zunächst konzentrieren wir uns auf die LSP-Nutzbarkeit.
Die Ziele sollen unter den folgenden Anforderungen erreicht werden:
-
Unabhängigkeit: Das Programmiererlebnis der Nutzer darf nicht beeinträchtigt werden.
-
Privatsphäre: Der Code der Nutzer sollte sicher sein (z. B. indem alles lokal bleibt).
-
Nebenläufigkeit: Mehrere KIs sollten ihre Arbeit gleichzeitig ausführen können.
-
Universalität: Es sollte für alle Sprachen und alle Workspace-Konfigurationen funktionieren.
-
Wartbarkeit: Es sollte mit so wenig und so gut isolierbarem Code wie möglich implementiert sein.
-
Geschwindigkeit: Es sollte nirgendwo minutenlange Verzögerungen geben, und es sollte genug Durchsatz für Hunderte von KI-Branches vorhanden sein.
Viele dieser Punkte spiegeln die Realität wider, einen Code-Editor für mehr als hunderttausend Nutzer zu bauen. Wir wollen auf keinen Fall das Programmiererlebnis von irgendjemandem negativ beeinflussen.
Erreichen von LSP-Nutzbarkeit
KI-Systemen zu erlauben, für ihre Änderungen Lints zu erhalten, gehört zu den wirksamsten Möglichkeiten, die Qualität der Codegenerierung zu verbessern, wenn das zugrunde liegende Sprachmodell unverändert bleibt. Lints helfen nicht nur dabei, von 90 % funktionierendem Code zu 100 % funktionierendem Code zu kommen, sie sind auch in kontextbeschränkten Situationen sehr hilfreich, wenn die KI beim ersten Versuch eine fundierte Vermutung anstellen muss, welche Methode oder welchen Dienst sie aufrufen soll. Die Lints können dabei helfen, Stellen zu identifizieren, an denen die KI nach mehr Informationen fragen muss.

LSP-Nutzbarkeit ist auch einfacher als Ausführbarkeit, weil fast alle Language Server mit Dateien arbeiten können, die nicht im Dateisystem gespeichert sind (und wie wir später sehen werden, macht die Einbeziehung des Dateisystems die Dinge erheblich schwieriger). Fangen wir also hier an! Im Sinne unserer fünften Anforderung, der Wartbarkeit, haben wir zuerst die einfachsten möglichen Lösungen ausprobiert.
Die einfachen Lösungen, die nicht funktionieren
Da Cursor ein Fork von VS Code ist, haben wir bereits sehr einfachen Zugriff auf Language-Server. In VS Code wird jede geöffnete Datei durch ein TextModel-Objekt repräsentiert, das den aktuellen Zustand der Datei im Speicher hält. Language-Server lesen aus diesen TextModel-Objekten statt von der Festplatte, wodurch sie dir Vervollständigungen und Lints während des Tippens liefern können (und nicht nur beim Speichern).
Angenommen, eine KI nimmt eine Änderung an der Datei lib.ts vor. Wir können das bestehende TextModel-Objekt, das lib.ts entspricht, offensichtlich nicht verändern, weil du es gleichzeitig bearbeiten könntest. Eine naheliegende Idee ist dennoch, eine Kopie des TextModel-Objekts zu erstellen, diese Kopie von jeder realen Datei auf der Festplatte zu lösen und die KI dieses Objekt bearbeiten zu lassen und daraus Lints zu erhalten. Das ließe sich mit den folgenden 6 Zeilen Code umsetzen.
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// kopiertes In-Memory-TextModel erstellen und die KI-Bearbeitung darauf anwenden
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// 2 Sekunden warten, damit Language Server das neue TextModel-Objekt verarbeiten können
await new Promise((resolve) => setTimeout(resolve, 2000));
// Lints vom Marker-Service lesen, der intern basierend auf der Sprache zur richtigen Erweiterung weiterleitet
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}Diese Lösung ist in Bezug auf Wartbarkeit eindeutig hervorragend. Sie ist auch hinsichtlich Universalität sehr gut, weil die meisten Leute bereits die richtigen, sprachspezifischen Erweiterungen für ihr Projekt installiert und konfiguriert haben. Nebenläufigkeit und Datenschutz sind trivial erfüllt.
Das Problem ist die Unabhängigkeit. Auch wenn das Anlegen einer Kopie von TextModel bedeutet, dass wir nicht direkt die Datei verändern, die der Nutzer bearbeitet, teilen wir dem Sprachserver – demselben Sprachserver, den der Nutzer verwendet – dennoch die Existenz unserer kopierten Datei mit. Das führt zu Problemen: „Go to References“-Ergebnisse werden unsere kopierte Datei enthalten, Sprachen wie Go, die einen standardmäßigen Namensraum mit Gültigkeit über mehrere Dateien hinweg haben, werden sich über doppelte Deklarationen aller Funktionen sowohl in der Kopie als auch in der Originaldatei beschweren, die der Nutzer möglicherweise bearbeitet, und Sprachen wie Rust, bei denen Dateien nur eingebunden werden, wenn sie explizit irgendwo importiert werden, liefern überhaupt keine Fehler. Es dürfte noch eine Menge weiterer Probleme dieser Art geben.
Man könnte denken, dass diese Probleme geringfügig klingen, aber Unabhängigkeit ist für uns absolut entscheidend. Wenn wir die normale Experience beim Bearbeiten von Code auch nur ein wenig verschlechtern, spielt es keine Rolle, wie gut unsere KI‑Funktionen sind – die Leute, mich eingeschlossen, würden Cursor einfach nicht benutzen.
Wir haben auch ein paar andere, letztlich verworfene Ideen in Betracht gezogen: eigene Instanzen von tsc oder gopls oder rust-analyzer außerhalb der VS Code‑Infrastruktur zu starten, den Extension-Host-Prozess zu duplizieren, in dem alle VS Code‑Erweiterungen laufen, damit wir zwei Kopien jeder Sprachserver-Erweiterung ausführen können, und alle populären Sprachserver zu forken, um mehrere verschiedene Versionen von Dateien zu unterstützen, und diese Erweiterungen dann in Cursor zu bündeln.
Die aktuelle Implementierung des Shadow-Workspaces
Wir haben den Shadow-Workspace letztendlich als verstecktes Fenster implementiert: Immer wenn eine KI Lints für Code sehen möchte, den sie geschrieben hat, erzeugen wir ein verstecktes Fenster für den aktuellen Workspace und führen die Änderung stattdessen in diesem Fenster aus, um anschließend die Lints zurückzumelden. Wir verwenden das versteckte Fenster zwischen Anfragen wieder. Das verschafft uns (fast*) vollständige LSP-Nutzbarkeit, während alle Anforderungen (fast*) vollständig erfüllt werden. Die Sternchen werden später erläutert.
Ein vereinfachtes Architekturdiagramm ist in Abbildung 4 dargestellt.
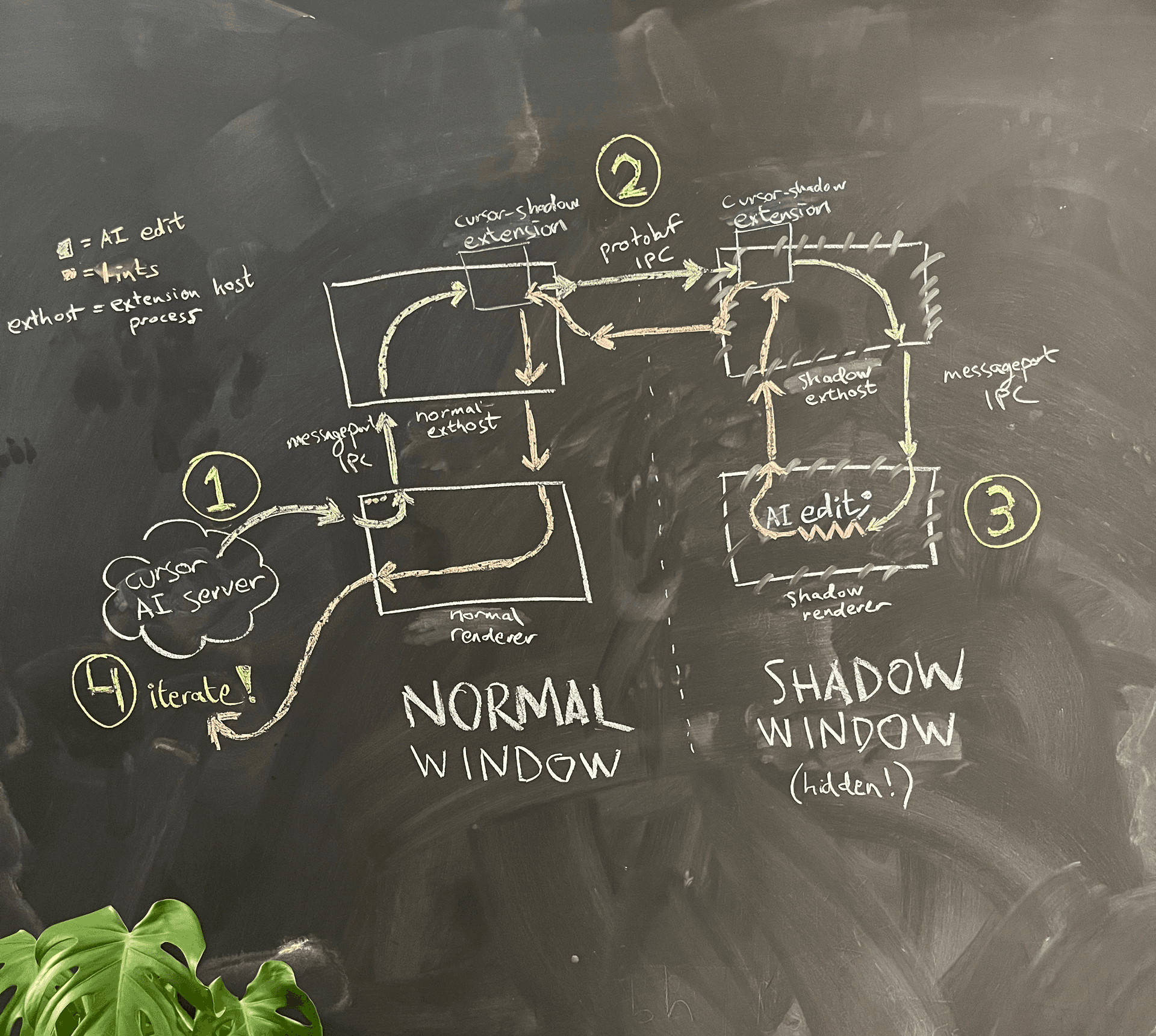
Die KI läuft im Renderer-Prozess des normalen Fensters. Wenn sie Lints für den Code sehen möchte, den sie geschrieben hat, bittet der Renderer-Prozess den Main-Prozess, ein verstecktes Shadow-Fenster im selben Ordner zu erzeugen.
Aufgrund des Electron-Sandboxings können die beiden Renderer-Prozesse nicht direkt miteinander kommunizieren. Eine Option, die wir in Betracht gezogen haben, war, die sorgfältige Message-Port-Erstellungslogik wiederzuverwenden, die VS Code implementiert hat, um dem Renderer-Prozess die Kommunikation mit dem Extension-Host-Prozess zu ermöglichen, und sie zu nutzen, um unseren eigenen Message-Port-IPC zwischen dem normalen Fenster und dem Shadow-Fenster aufzubauen. Aus Sorge um die Wartbarkeit haben wir uns für einen Hack entschieden: Wir verwenden den bestehenden Message-Port-IPC vom Renderer-Prozess zum Extension Host wieder und kommunizieren dann von Extension Host zu Extension Host über eine unabhängige IPC-Verbindung. Dort haben wir auch eine Quality-of-Life-Verbesserung eingeschmuggelt: Wir konnten nun gRPC und buf (das wir lieben) für die Kommunikation verwenden, anstatt die benutzerdefinierte und etwas fragile JSON-Serialisierungslogik von VS Code.
Dieses Setup ist von sich aus gut wartbar, da der hinzugefügte Code unabhängig von anderem Code ist und der Kerncode, der benötigt wird, um das Fenster zu verbergen, nur aus einer Zeile besteht (wenn man in Electron ein Fenster öffnet, kann man den Parameter show: false angeben, um es zu verstecken). Es erfüllt Universalität und Privatsphäre trivialerweise.
Glücklicherweise ist auch die Unabhängigkeit erfüllt! Das neue Fenster ist vollständig unabhängig vom Benutzer, sodass die KIs alle gewünschten Änderungen frei durchführen und dafür Lints erhalten können. Der Benutzer bemerkt davon nichts.
Es gibt ein Problem mit dem Shadow-Fenster: Das neue Fenster bringt naiv eine doppelt so hohe Speicherauslastung mit sich. Wir verringern die Auswirkungen, indem wir die Erweiterungen einschränken, die im Shadow-Fenster ausgeführt werden dürfen, es nach 15 Minuten Inaktivität automatisch beenden und sicherstellen, dass es explizit aktiviert werden muss. Dennoch stellt es eine Herausforderung für Parallelität dar: Wir können nicht einfach für jede KI ein neues Shadow-Fenster erzeugen. Glücklicherweise können wir hier einen der zentralen Unterschiede zwischen KIs und Menschen ausnutzen: KIs können beliebig lange pausiert werden, ohne es überhaupt zu bemerken. Wenn du insbesondere zwei KIs A und B hast, die jeweils Änderungen A1 gefolgt von A2 und B1 gefolgt von B2 vorschlagen, kannst du diese Änderungen miteinander verschachteln. Das Shadow-Fenster setzt zunächst den gesamten Ordnerzustand auf A1 zurück, holt die Lints und gibt sie an A zurück. Dann setzt es den gesamten Ordnerzustand auf B1 zurück, holt die Lints und gibt sie an B zurück. Und so weiter mit A2 und B2. In dieser Hinsicht ähneln KIs eher Computerprozessen (die von der CPU ebenfalls auf diese Weise ineinander verschachtelt werden, ohne es zu bemerken) als Menschen (die ein intrinsisches Zeitgefühl haben).
Alles zusammen ergibt eine einfache Protobuf-API, die unsere Hintergrund-KIs nutzen können, um ihre Änderungen zu verfeinern, ohne den Benutzer in irgendeiner Weise zu beeinflussen.
Die versprochenen Sternchen: Einige Language Server sind darauf angewiesen, dass Code auf die Festplatte geschrieben wird, bevor sie Lints melden. Das Hauptbeispiel ist der rust-analyzer Language Server, der einfach ein projektweites cargo check ausführt, um die Lints zu erhalten, und nicht mit dem virtuellen Dateisystem von VS Code integriert ist (siehe dieses Issue als Referenz). Daher unterstützt der Shadow Workspace derzeit noch keine LSP-Funktionalität für Rust, es sei denn, der Nutzer verwendet die veraltete RLS-Extension.
Erreichen von Ausführbarkeit
Ausführbarkeit ist der Punkt, an dem es sowohl interessant als auch kompliziert wird. Wir konzentrieren uns derzeit auf KI-Modelle mit kurzer Laufzeit für Cursor – zum Beispiel darauf, Funktionen im Hintergrund für Sie zu implementieren, während Sie sie verwenden, anstatt ganze PRs umzusetzen – daher haben wir Ausführbarkeit noch nicht implementiert. Nichtsdestotrotz ist es spannend, durchzuspielen, wie man sie erreichen kann.
Um Code auszuführen, muss er im Dateisystem gespeichert werden. Viele Projekte haben außerdem Seiteneffekte auf dem Datenträger (man denke an Build-Caches und Logdateien). Daher können wir das Shadow-Fenster nicht mehr im selben Ordner wie der Benutzer starten. Für die perfekte Ausführbarkeit aller Projekte benötigen wir außerdem Isolation auf Netzwerkebene, aber vorerst konzentrieren wir uns darauf, Isolation auf Datenträgerebene zu erreichen.
Die einfachste Idee: cp -r
Die einfachste Idee ist, den Ordner des Benutzers rekursiv in ein /tmp-Verzeichnis zu kopieren, dann die KI-Änderungen anzuwenden, die Dateien zu speichern und den Code dort auszuführen. Für die nächste Änderung durch eine andere KI würden wir ein rm -rf ausführen, gefolgt von einem neuen cp -r, um sicherzustellen, dass der Shadow-Workspace mit dem Workspace des Benutzers synchron bleibt.
Das Problem ist die Geschwindigkeit: cp -r ist wirklich langsam. Entscheidend ist, dass wir, um ein Projekt ausführen zu können, nicht nur den Quellcode kopieren müssen, sondern auch alle unterstützenden buildbezogenen Dateien. Konkret müssen wir in JavaScript-Projekten die node_modules, in Python-Projekten das venv und in Rust-Projekten das target kopieren. Diese Ordner sind in der Regel riesig, selbst bei mittelgroßen Projekten – das besiegelt das Ende des naiven cp -r-Ansatzes.
Symlinks, Hardlinks, Copy-on-Writes
Das Kopieren und Erstellen großer Ordnerstrukturen muss nicht extrem langsam sein! Ein Beleg dafür ist bun, das häufig weniger als eine Sekunde benötigt, um zwischengespeicherte Abhängigkeiten in node_modules zu installieren. Unter Linux werden Hardlinks verwendet, was schnell ist, weil keine tatsächliche Datenbewegung stattfindet. Unter macOS kommt der clonefile-Syscall zum Einsatz, eine relativ neue Ergänzung, die ein Copy-on-Write einer Datei oder eines Ordners durchführt.
Leider braucht unser mittelgroßes Monorepo selbst für ein cp -c-Clonefile 45 Sekunden, bis der Vorgang abgeschlossen ist. Das ist zu langsam, um es vor jeder Shadow-Workspace-Anfrage auszuführen. Hardlinks sind riskant, weil alles, was man im Shadow-Ordner ausführt, versehentlich die echten Dateien im ursprünglichen Repository verändern könnte. Symlinks sind ähnlich problematisch und haben zusätzlich das Problem, dass sie nicht transparent behandelt werden, was oft zusätzliche Konfiguration erfordert (z. B. die Node.js-Flagge --preserve-symlinks).
Man könnte sich vorstellen, dass ein Clonefile (oder sogar ein einfaches cp -r) funktionieren würde, wenn es mit einem cleveren Verfahren zur Nachverfolgung gekoppelt ist, sodass der Ordner nicht vor jeder Anfrage erneut kopiert werden muss. Um Korrektheit sicherzustellen, müssten wir alle Dateiänderungen im Ordner der Nutzer seit der letzten vollständigen Kopie und alle Dateiänderungen im kopierten Ordner überwachen und vor jeder Anfrage Letztere rückgängig machen und Erstere erneut anwenden. Wann immer die Änderungshistorie auf einer der beiden Seiten zu groß wird, um sie nachzuverfolgen, könnten wir eine neue Vollkopie durchführen und den Zustand zurücksetzen. Das könnte funktionieren, wirkt aber fehleranfällig, fragil und, ehrlich gesagt, etwas unschön, um etwas zu erreichen, das so simpel klingt.
Was wir eigentlich wollen: ein Kernel-Level-Ordnerproxy
Was wir eigentlich wollen, ist einfach: Wir wollen, dass ein Schattenordner A′ für alle Anwendungen, die die regulären Dateisystem-APIs verwenden, identisch wie der Ordner A des Nutzers erscheint – mit der Möglichkeit, schnell eine kleine Menge von Override-Dateien zu konfigurieren, deren Inhalt stattdessen aus dem Speicher gelesen wird. Außerdem wollen wir, dass alle Schreibzugriffe auf Ordner A′ in den Override-Speicher im Arbeitsspeicher und nicht auf die Festplatte geschrieben werden. Kurz gesagt: Wir wollen einen Proxy-Ordner mit konfigurierbaren Overrides, und wir sind zufrieden damit, die Override-Tabelle vollständig im Speicher zu halten. Dann können wir unser Schattenfenster innerhalb dieses Proxy-Ordners starten und damit perfekte Unabhängigkeit auf Festplattenebene erreichen.
Entscheidend ist, dass wir Kernel-Level-Unterstützung für den Ordnerproxy brauchen, damit sämtlicher laufender Code weiterhin read- und write-Systemaufrufe ohne Änderungen verwenden kann. Ein Ansatz besteht darin, eine Kernel-Erweiterung 13 zu erstellen, die sich im virtuellen Dateisystem des Kernels als Backend für den Schattenordner registriert und das oben skizzierte einfache Verhalten implementiert.
Unter Linux können wir dies stattdessen im Userspace mit FUSE („Filesystem in Userspace“) tun. FUSE ist ein Kernelmodul, das in den meisten Linux-Distributionen standardmäßig bereits enthalten ist und die Dateisystemaufrufe an einen Userspace-Prozess weiterleitet. Das macht die Implementierung des Ordnerproxys noch einfacher. Eine einfache Beispielimplementierung des Ordnerproxys könnte wie folgt aussehen, hier in C++ dargestellt.
Zuerst binden wir die FUSE-Bibliothek für den Userspace ein, die für die Kommunikation mit dem FUSE-Kernelmodul verantwortlich ist. Außerdem definieren wir den Zielordner (den Ordner des Nutzers) und die im Arbeitsspeicher gehaltene Map der Overrides.
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// weitere Includes...
using namespace std;
// der Proxy-Ordner, den wir nicht ändern möchten
string target_folder = "/path/to/target/folder";
// die anzuwendenden In-Memory-Überschreibungen
unordered_map<string, vector<char>> overrides;Dann definieren wir unsere benutzerdefinierte Funktion read, um zu prüfen, ob die Overrides einen Eintrag für diesen Pfad enthalten, und falls nicht, einfach aus dem Zielordner zu lesen.
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// prüfen, ob der Pfad in den Overrides enthalten ist
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// falls ja, den Inhalt des Overrides zurückgeben
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// andernfalls die Datei aus dem proxierten Ordner öffnen und lesen
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}Unsere eigene write-Funktion schreibt lediglich in die Overrides-Map.
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// immer in die Overrides schreiben
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}Abschließend registrieren wir unsere benutzerdefinierten Funktionen in FUSE.
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}Eine vollständige Implementierung müsste die gesamte FUSE-API abdecken, einschließlich readdir, getattr und lock, aber die Funktionen wären den oben gezeigten sehr ähnlich. Für jede neue Lint-Anfrage können wir die Overrides-Map einfach auf nur die Änderungen dieser spezifischen KI zurücksetzen, was praktisch sofort geschieht. Wenn wir eine Speicherexplosion sicher ausschließen wollten, könnten wir die Overrides-Map außerdem auf der Festplatte halten (mit etwas zusätzlichem Verwaltungsaufwand).
Mit perfekter Kontrolle über die Umgebung würden wir dies wahrscheinlich stattdessen als natives Kernelmodul implementieren, um den Overhead der zusätzlichen Kontextwechsel zwischen User- und Kernel-Mode durch FUSE zu vermeiden. 14
...Aber: Walled Gardens
Unter Linux funktioniert der FUSE-Ordner-Proxy hervorragend, aber die meisten unserer Nutzer verwenden macOS oder Windows, von denen keines eine integrierte FUSE-Implementierung hat. Leider kommt es auch nicht in Frage, eine Kernel-Erweiterung auszuliefern: Auf Macs mit Apple Silicon besteht die einzige Möglichkeit für Nutzer, eine Kernel-Erweiterung zu installieren, darin, den Computer neu zu starten, dabei eine spezielle Taste gedrückt zu halten, um in den Recovery-Modus zu gelangen, und anschließend auf „Reduced Security“ herabzustufen. Nicht auslieferbar!
Da FUSE teilweise im Kernel laufen muss, haben Drittanbieter-FUSE-Implementierungen wie macFUSE dasselbe Problem, dass es praktisch unmöglich ist, Nutzer zur Installation zu bewegen.
Es gab Versuche, diese Einschränkung kreativ zu umgehen. Ein Ansatz besteht darin, ein netzwerkbasiertes Dateisystem zu verwenden, das macOS nativ unterstützt (z. B. NFS oder SMB), und darunter eine FUSE-API zu legen. Es gibt einen Open-Source-Prototyp eines lokalen Servers mit einer FUSE-ähnlichen API, der auf NFS aufsetzt und unter xetdata/nfsserve gehostet wird, und das proprietäre Projekt macOS-FUSE-t unterstützt Backends, die sowohl auf NFS als auch auf SMB basieren.
Problem gelöst? Nicht wirklich... Dateisysteme sind komplizierter, als nur Dateien zu lesen, zu schreiben und aufzulisten! Hier beschwert sich Cargo, weil frühere NFS-Versionen, auf denen die xetdata/nfsserve-Implementierung aufbaut, keine Dateisperren (File Locking) unterstützen.

MacOS-FUSE-t basiert auf NFSv4, das tatsächlich Dateisperren unterstützt, aber das GitHub-Repository enthält nichts außer drei Nicht-Quellcode-Dateien (Attributions.txt, License.txt, README.md) und wurde von einem GitHub-Account mit dem verdächtig zweckgebundenen Benutzernamen macos-fuse-t ohne weitere Informationen erstellt. Offensichtlich können wir unseren Nutzern keine zufälligen Binärdateien ausliefern... Die offenen Issues deuten außerdem auf einige grundlegendere Probleme des NFS/SMB-basierten Ansatzes hin, die größtenteils mit Kernel-Bugs von Apple zusammenhängen.
Was bleibt uns? Entweder ein neuer kreativer Ansatz oder ... Politik! Apples jahrzehntelange Reise zum Ausphasen von Kernel-Erweiterungen hat dazu geführt, dass sie immer mehr User-Level-APIs öffnen (wie z. B. DriverKit), und ihre integrierte Unterstützung für alte Dateisysteme wurde kürzlich in den User-Space verlagert. Ihr Open-Source-MS-DOS-Code verweist hier auf ein privates Framework namens FSKit, was sehr vielversprechend klingt! Es wirkt möglich, dass wir mit ein bisschen Politik erreichen könnten, dass sie FSKit finalisieren und für externe Entwickler freigeben (oder vielleicht planen sie das ohnehin schon?), womit wir eventuell auch für macOS eine Lösung für das Ausführbarkeitsproblem hätten.
Offene Fragen
Wie wir gesehen haben, ist das scheinbar einfache Problem, KIs im Hintergrund iterativ an Code arbeiten zu lassen, in Wirklichkeit ziemlich komplex. Der Shadow-Workspace war ein 1‑wöchiges 1‑Personen‑Projekt, um eine Implementierung zu erstellen, die unseren unmittelbaren Bedarf abdeckt, der darin bestand, der KI Lints anzeigen zu können. In Zukunft planen wir, ihn so zu erweitern, dass er auch das Ausführbarkeitsproblem löst. Ein paar offene Fragen:
-
Gibt es eine andere Möglichkeit, den einfachen Proxy‑Ordner, den wir uns vorstellen, zu realisieren, ohne eine Kernel‑Extension zu erstellen oder die FUSE‑API zu verwenden? FUSE versucht ein größeres Problem zu lösen (jede Art von Dateisystem), und deshalb erscheint es plausibel, dass es einige obskure APIs auf macOS und Windows geben könnte, die für unseren Ordner‑Proxy funktionieren würden, aber nicht für eine allgemeine FUSE‑Implementierung.
-
Wie genau sieht das Konzept für den Proxy‑Ordner unter Windows aus? Würde etwas wie WinFsp einfach funktionieren, oder gibt es damit Installations‑, Performance‑ oder Sicherheitsprobleme? Ich habe die meiste Zeit damit verbracht, herauszufinden, wie man den Ordner‑Proxy auf macOS umsetzt.
-
Gibt es vielleicht eine Möglichkeit, DriverKit auf macOS zu verwenden und ein virtuelles USB‑Gerät zu simulieren, das als Proxy‑Ordner fungiert? Ich bezweifle es, aber ich habe mir die API nicht genau genug angesehen, um mit Sicherheit sagen zu können, dass es unmöglich ist.
-
Wie können wir Unabhängigkeit auf Netzwerkebene erreichen? Ein spezielles Szenario, das zu berücksichtigen ist, ist, wenn die KI einen Integrationstest debuggen möchte, bei dem der Code auf drei Microservices aufgeteilt ist. Möglicherweise wollen wir etwas VM‑Ähnliches einsetzen, obwohl das mehr Arbeit erfordern würde, um Gleichwertigkeit für die gesamte Umgebungskonfiguration und die gesamte installierte Software sicherzustellen.
-
Gibt es eine Möglichkeit, aus dem lokalen Workspace der Nutzer:innen einen identischen Remote‑Workspace zu erstellen, mit so wenig nötigem Setup durch die Nutzer:innen wie möglich? In der Cloud könnten wir FUSE out‑of‑the‑box verwenden (oder sogar ein Kernel‑Modul, falls aus Performance‑Gründen gewünscht), ohne irgendwelche politischen Hürden, und wir könnten außerdem keinen zusätzlichen Speicherverbrauch für die Nutzer:innen und vollständige Unabhängigkeit garantieren. Für Nutzer:innen, denen Datenschutz weniger wichtig ist, könnte das eine gute Alternative sein. Eine Proto‑Idee ist eine Art automatisch abgeleiteter Docker‑Container durch Beobachtung des Systems (eventuell durch eine Kombination aus Skripten, die erkennen, was auf der Maschine läuft, und dem Einsatz von Sprachmodellen, um ein Dockerfile zu schreiben).
Wenn Sie gute Ideen zu einer dieser Fragen haben, schreiben Sie mir bitte eine E‑Mail an arvid@cursor.com. Und falls Sie an Themen wie diesen arbeiten möchten, wir stellen ein.