Dynamic context discovery
Coding-Agents verändern rasant, wie Software entwickelt wird. Ihre schnelle Verbesserung beruht sowohl auf verbesserten agentischen Modellen als auch auf besserem Kontext-Engineering, um sie zu steuern.
Der Agent-Harness von Cursor – also die Anweisungen und Tools, die wir dem Modell bereitstellen – wird für jedes neue Frontier-Modell, das wir unterstützen, individuell optimiert. Es gibt jedoch Verbesserungen im Kontext-Engineering, die wir vornehmen können, etwa dabei, wie wir Kontext erfassen und die Token-Nutzung über eine lange Trajektorie hinweg optimieren, die für alle Modelle innerhalb unseres Harnesses gelten.
Da Modelle als Agents besser geworden sind, haben wir Erfolg damit, anfangs weniger Details bereitzustellen, sodass es für den Agenten einfacher ist, relevanten Kontext selbst abzurufen. Dieses Muster nennen wir dynamische Kontextermittlung, im Gegensatz zu statischem Kontext, der immer einbezogen wird.
Dateien für dynamische Kontextermittlung
Dynamische Kontextermittlung ist deutlich token-effizienter, da nur die notwendigen Daten in das Kontextfenster geladen werden. Sie kann außerdem die Antwortqualität des Agents verbessern, indem sie die Menge potenziell verwirrender oder widersprüchlicher Informationen im Kontextfenster reduziert.
So nutzen wir dynamische Kontextermittlung in Cursor:
- Lange Tool-Antworten in Dateien umwandeln
- Chatverlauf bei der Zusammenfassung berücksichtigen
- Den offenen Standard „Agent Skills“ unterstützen
- Nur die benötigten MCP-Tools effizient laden
- Alle integrierten Terminalsitzungen wie Dateien behandeln
1. Lange Tool-Antworten in Dateien umwandeln
Tool-Aufrufe können das Kontextfenster stark vergrößern, indem sie eine umfangreiche JSON-Antwort zurückgeben.
Für First-Party-Tools in Cursor, wie das Bearbeiten von Dateien und das Durchsuchen der Codebasis, können wir eine Aufblähung des Kontexts mit intelligenten Tool-Definitionen und schlanken Antwortformaten verhindern, aber Third-Party-Tools (also Shell-Befehle oder MCP-Aufrufe) erhalten diese Behandlung nicht automatisch.
Der gängige Ansatz, den Coding-Agents verwenden, ist das Abschneiden langer Shell-Ausgaben oder MCP-Ergebnisse. Das kann zu Datenverlust führen, einschließlich wichtiger Informationen, die du im Kontext haben wolltest. In Cursor schreiben wir die Ausgabe stattdessen in eine Datei und geben dem Agent die Fähigkeit, sie zu lesen. Der Agent ruft tail auf, um das Ende zu prüfen, und liest bei Bedarf mehr.
Das führt zu weniger unnötigen Zusammenfassungen, wenn die Kontextgrenzen erreicht werden.
2. Nutzung des Chatverlaufs bei Zusammenfassungen
Wenn das Kontextfenster des Modells ausgeschöpft ist, löst Cursor einen Zusammenfassungsschritt aus, um dem Agent ein neues Kontextfenster mit einer Zusammenfassung seiner bisherigen Arbeit zu geben.
Aber das Wissen des Agent kann sich nach der Zusammenfassung verschlechtern, da diese einer verlustbehafteten Komprimierung des Kontexts entspricht. Der Agent könnte entscheidende Details zu seiner Aufgabe vergessen haben. In Cursor verwenden wir den Chatverlauf als Dateien, um die Qualität der Zusammenfassung zu verbessern.


Nachdem die Grenze des Kontextfensters erreicht wurde oder der Nutzer sich entscheidet, manuell zusammenzufassen, geben wir dem Agent einen Verweis auf die Verlaufsdatei. Wenn der Agent erkennt, dass er mehr Details benötigt, die in der Zusammenfassung fehlen, kann er im Verlauf danach suchen, um sie wiederherzustellen.
3. Unterstützung des offenen Standards „Agent Skills“
Cursor unterstützt Agent Skills, einen offenen Standard, um Coding-Agents mit spezialisierten Fähigkeiten zu erweitern. Ähnlich wie andere Arten von Rules werden Skills durch Dateien definiert, die dem Agent vorgeben, wie eine domänenspezifische Aufgabe auszuführen ist.
Skills enthalten außerdem einen Namen und eine Beschreibung, die als „statischer Kontext“ im System-Prompt eingebunden werden können. Der Agent kann dann eine dynamische Kontextsuche durchführen, um relevante Skills zu laden, und dabei Tools wie grep und Cursors semantic search nutzen.
Skills können auch ausführbare Dateien oder Skripte bündeln, die für die Aufgabe relevant sind. Da es sich nur um Dateien handelt, kann der Agent leicht finden, was für einen bestimmten Skill relevant ist.
4. Nur die benötigten MCP-Tools effizient laden
MCP ist hilfreich, um auf geschützte Ressourcen hinter OAuth zuzugreifen. Das können Produktions-Logs, externe Designdateien oder interner Kontext und Dokumentation für ein Enterprise-Unternehmen sein.
Einige MCP-Server enthalten viele Tools, häufig mit langen Beschreibungen, was das Kontextfenster erheblich aufblähen kann. Die meisten dieser Tools werden nie verwendet, obwohl sie immer im Prompt enthalten sind. Das verstärkt sich, wenn du mehrere MCP-Server nutzt.
Es ist nicht realistisch zu erwarten, dass jeder MCP-Server dafür optimiert ist. Wir sind der Meinung, dass es die Verantwortung der Coding-Agents ist, den Kontextverbrauch zu reduzieren. In Cursor unterstützen wir dynamische Kontext-Ermittlung für MCP, indem wir Tool-Beschreibungen mit einem Ordner synchronisieren.1
Der Agent erhält jetzt nur noch eine kleine Menge statischen Kontextes, einschließlich der Namen der Tools, und wird dadurch dazu angeregt, Tools nachzuschlagen, wenn die Aufgabe es erfordert. In einem A/B-Test haben wir festgestellt, dass bei Durchläufen, in denen ein MCP-Tool aufgerufen wurde, diese Strategie die vom Agent insgesamt verwendeten Tokens um 46,9 % reduziert hat (statistisch signifikant, mit hoher Varianz in Abhängigkeit von der Anzahl der installierten MCPs).
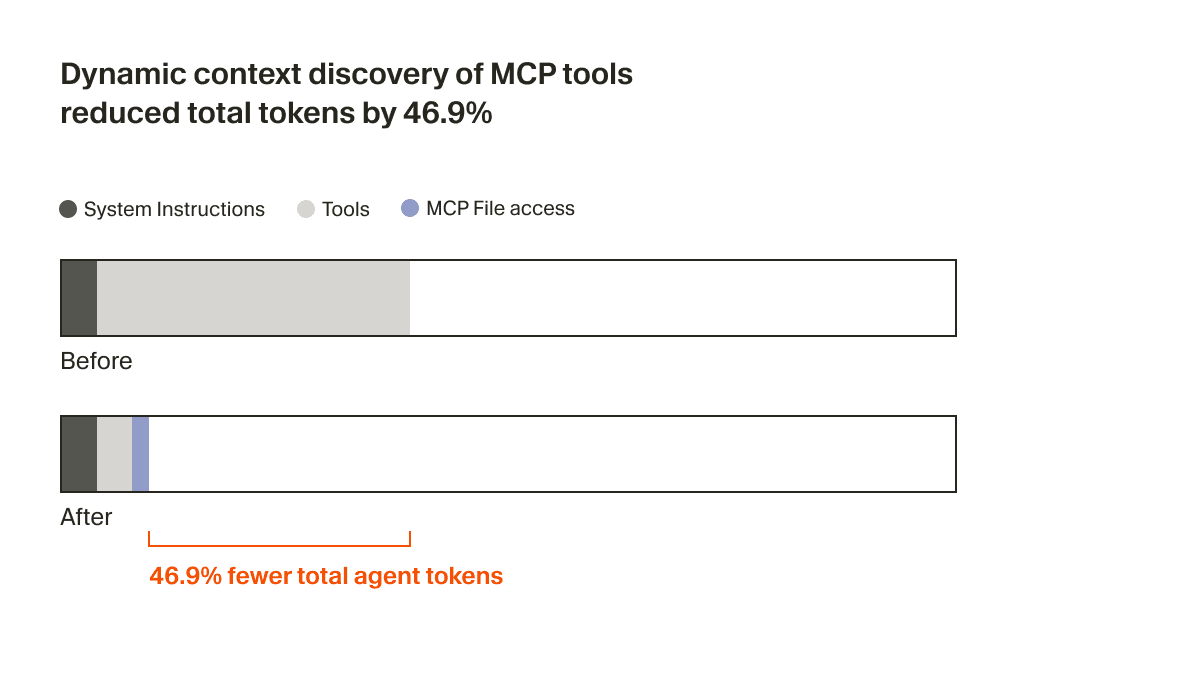
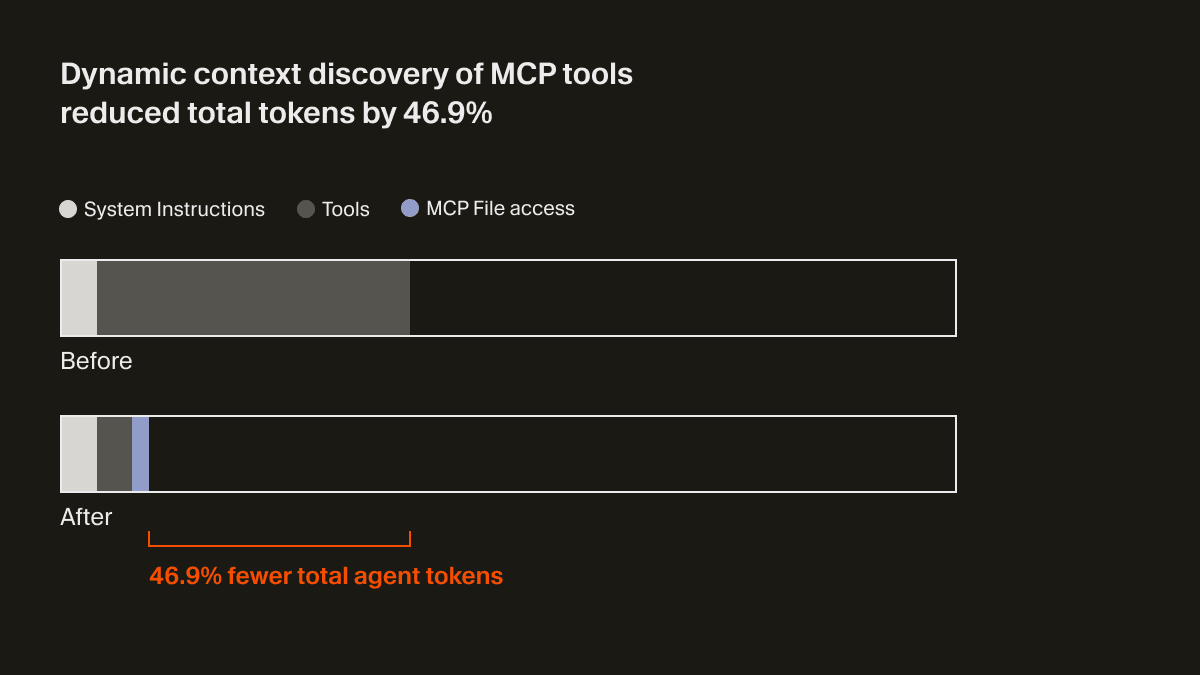
Dieser dateibasierte Ansatz ermöglicht außerdem, den Status von MCP-Tools an den Agent zu kommunizieren. Musste zum Beispiel früher ein MCP-Server erneut authentifiziert werden, vergaß der Agent diese Tools vollständig, was die Nutzer verwirrte. Jetzt kann er die Nutzer tatsächlich proaktiv darauf hinweisen, sich erneut zu authentifizieren.
5. Alle integrierten Terminalsitzungen wie Dateien behandeln
Anstatt die Ausgabe einer Terminalsitzung in die Agent-Eingabe kopieren und einfügen zu müssen, synchronisiert Cursor jetzt die Ausgaben des integrierten Terminals mit dem lokalen Dateisystem.
So kannst du leicht fragen: „Warum ist mein Befehl fehlgeschlagen?“ und der Agent versteht, worauf du dich beziehst. Da die Terminal-Historie lang sein kann, kann der Agent mit grep nur nach den relevanten Ausgaben suchen – das ist besonders nützlich für Logs eines lange laufenden Prozesses wie eines Servers.
Dies entspricht dem, was CLI-basierte Coding-Agents sehen: frühere Shell-Ausgaben stehen im Kontext zur Verfügung, werden aber dynamisch ermittelt statt statisch eingefügt.
Einfache Abstraktionen
Es ist noch nicht klar, ob Dateien die endgültige Schnittstelle für LLM-basierte Tools sein werden.
Aber während sich Coding-Agents schnell verbessern, haben sich Dateien als einfacher und leistungsstarker Grundbaustein erwiesen – und als sicherere Wahl als eine weitere Abstraktion, die der Zukunft nicht vollständig gerecht werden kann. Bleiben Sie dran – wir werden in diesem Bereich noch viele spannende Entwicklungen vorstellen.
Diese Verbesserungen werden in den kommenden Wochen für alle Nutzer verfügbar sein. Die in diesem Blogpost beschriebenen Techniken sind die Arbeit vieler Cursor-Mitarbeiter, darunter Lukas Moller, Yash Gaitonde, Wilson Lin, Jason Ma, Devang Jhabakh und Jediah Katz. Wenn Sie daran interessiert sind, die schwierigsten und ambitioniertesten Coding-Aufgaben mit KI zu lösen, freuen wir uns, von Ihnen zu hören. Kontaktieren Sie uns unter hiring@cursor.com.
- Wir haben einen Ansatz mit Toolsuche in Betracht gezogen, aber dadurch würden Tools in einem flachen Index verteilt. Stattdessen erstellen wir einen Ordner pro Server und halten so die Tools jedes Servers logisch gruppiert. Wenn das Modell einen Ordner auflistet, sieht es alle Tools dieses Servers zusammen und kann sie als zusammenhängende Einheit verstehen. Dateien ermöglichen außerdem leistungsfähigere Suchfunktionen. Der Agent kann vollständige
rg-Parameter oder sogarjqverwenden, um Tool-Beschreibungen zu filtern. ↩