我们如何在 Cursor 中比较模型质量
注意: CursorBench 会随着智能体功能的演进持续更新。当前生产版本为 CursorBench 3.1;最新排行榜请参见该页面。
开发者正让编程智能体承担更长、更复杂的任务,这些任务跨越多个文件、工具和步骤。随着这些请求的范围不断扩大,用于衡量智能体性能的评测也需要随之演进。
在 Cursor,我们采用线上与线下结合的混合评测流程,让我们对模型质量的理解始终与开发者的真实工作方式保持一致。
线下部分使用 CursorBench,这是我们基于工程团队真实 Cursor 会话构建的内部评测套件。由于任务来自真实的 Cursor 用量,而不是公开代码仓库,CursorBench 不仅更能区分不同模型,也比公开基准更贴近开发者的真实结果。
我们构建 CursorBench 是为了衡量智能体性能的多个维度,包括解决方案正确性、代码质量、效率和交互行为。本文聚焦于解决方案正确性的结果,但在实际中,我们会沿所有这些维度评估智能体。
更新,2026 年 5 月: 此后,我们已将 CursorBench 更新到 3.1,并加入了更难的问题。由于题目分布发生了变化,CursorBench 3.1 的分数可能会与本文中的数字和图表有所不同,因此应仅在同一评测版本内进行比较。


我们还通过在真实流量上进行的受控分析来补充 CursorBench。这些在线评估能发现线下评测套件遗漏的回归问题,比如智能体的输出在评分器看来是正确的,但对实际使用产品的开发者来说体验却更差。
总之,这个在线-离线闭环让我们对模型质量的判断能够随着工作流变化而始终立足于生产环境,并帮助我们在 Cursor 中打造最佳的智能体体验。
公开基准的局限性
一个好的基准需要能够区分那些在实际使用中表现不同的模型,同时与开发者对这些模型的真实体验相一致。而公开的离线评测在这两方面都存在困难。
第一个问题是一致性。随着开发者借助智能体承担的工作日益复杂且多样,静态或不匹配的基准最终会完全测错方向。例如,大多数 SWE 基准仍然聚焦于修复缺陷任务。类似地,Terminal-Bench 更强调广义的谜题式任务,例如根据棋盘局面找出最佳走法。我们发现,这些任务与开发者要求智能体完成的编程工作并不契合。
第二个问题是评分。许多公开基准任务都假设只有一小组正确解法,但大多数开发者请求本身留有足够多的未明确之处,因此往往存在多种有效方案。因此,基准往往要么惩罚其他同样正确的方法,要么附加人为设计的要求来消除这种不明确性。这两种做法都无法准确评估真实性能。
第三个问题是污染。SWE-bench Verified、Pro 和 Multilingual 都从公开代码库中抽取任务,而这些任务最终会进入模型训练数据,从而抬高分数。OpenAI 最近 在发现前沿模型可以凭记忆复现标准补丁,并且近 60% 未解决问题的测试存在缺陷后,已完全停止报告 SWE-bench Verified 的结果。
结果是,在前沿水平上,这些基准已经无法区分那些对开发者而言实用价值截然不同的模型。
构建 CursorBench
我们使用 Cursor Blame 为 CursorBench 收集任务,它可以将已提交的代码追溯到生成该代码的智能体请求。这为我们提供了开发者查询与标准答案解决方案的自然配对。许多任务来自我们的内部代码库和受控来源,从而降低了模型在训练阶段见过这些任务的风险。我们每隔几个月就会更新一次这套基准,以跟踪开发者使用智能体方式的变化。
在我们的正确性评估中,问题规模从初始版本到当前的 CursorBench-3 大致翻了一倍,无论从代码行数还是平均文件数来看都是如此。CursorBench-3 任务涉及的代码行数,明显多于 SWE-bench Verified、Pro 或 Multilingual 中的任务。虽然代码行数并不是衡量难度的完美指标,但该指标上的增长反映了我们将更具挑战性的任务纳入 CursorBench 的方式,例如处理 monorepo 的多工作区环境、排查生产日志,以及执行长时间运行的实验。
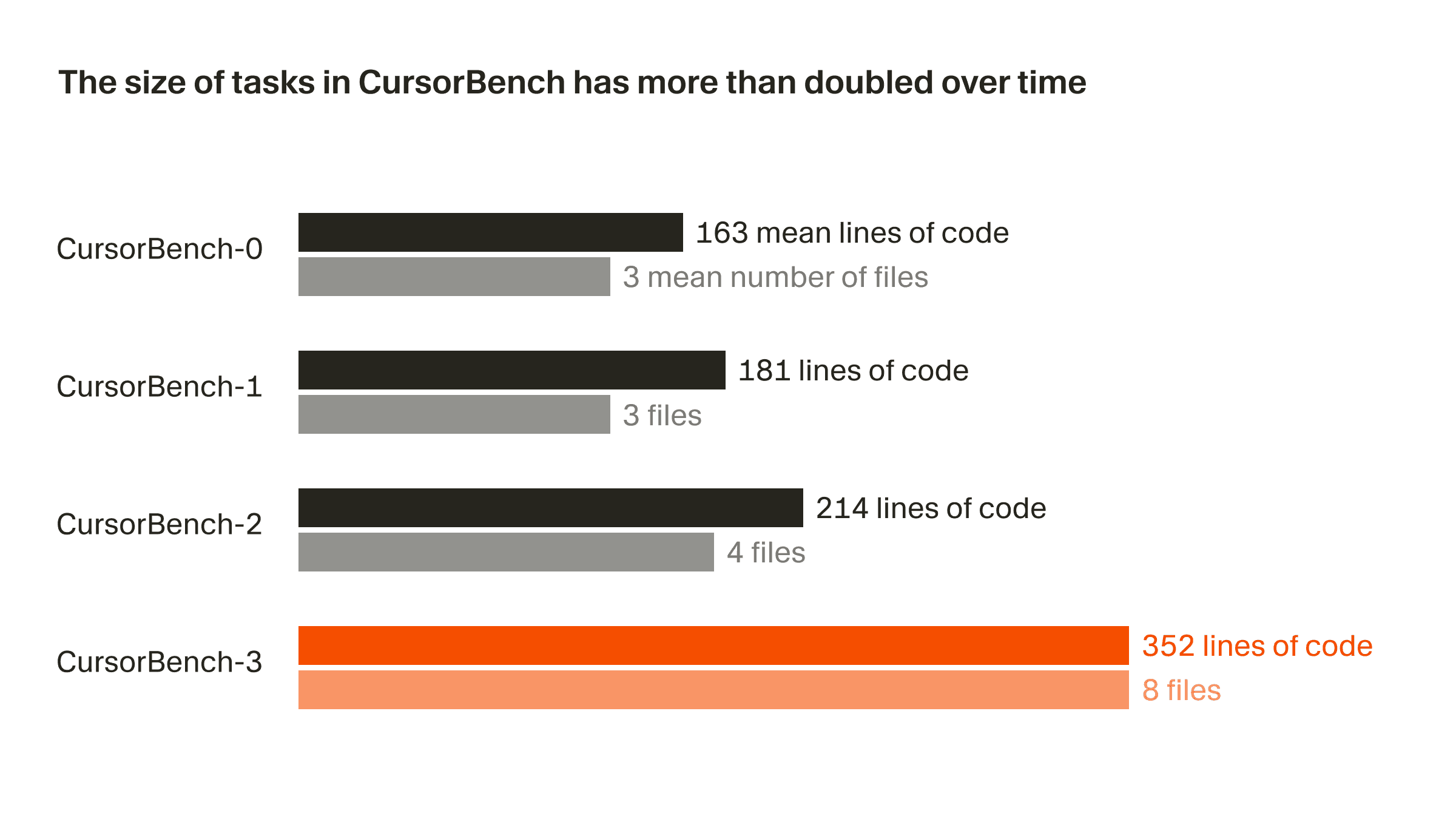
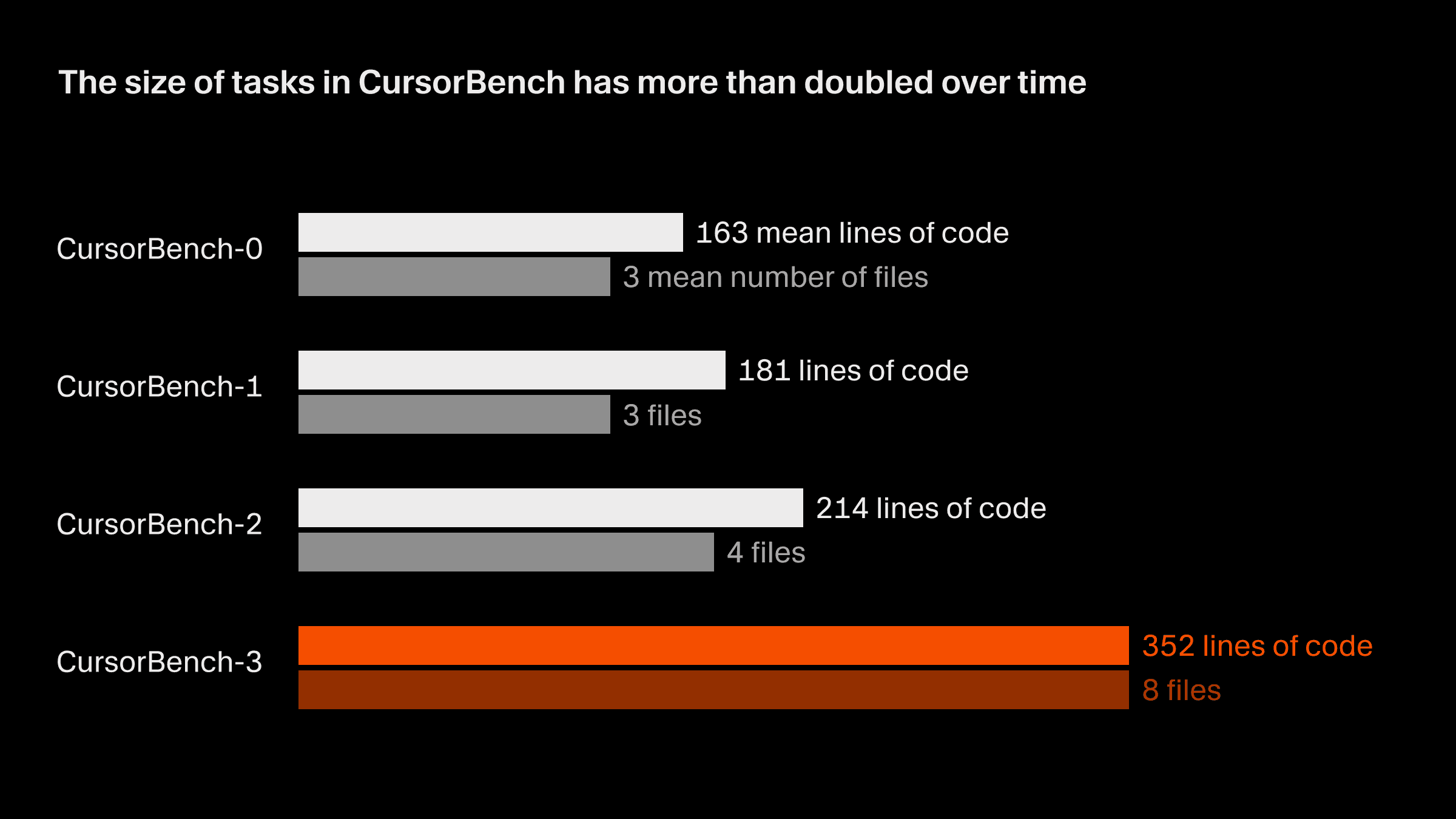
CursorBench 的任务也更贴近开发者与智能体交流时那种信息不充分、且常带歧义的表达方式。与公开基准中来源于 GitHub 的详细问题相比,我们的任务描述刻意保持简短,并使用智能体评分器对其进行可靠评分。


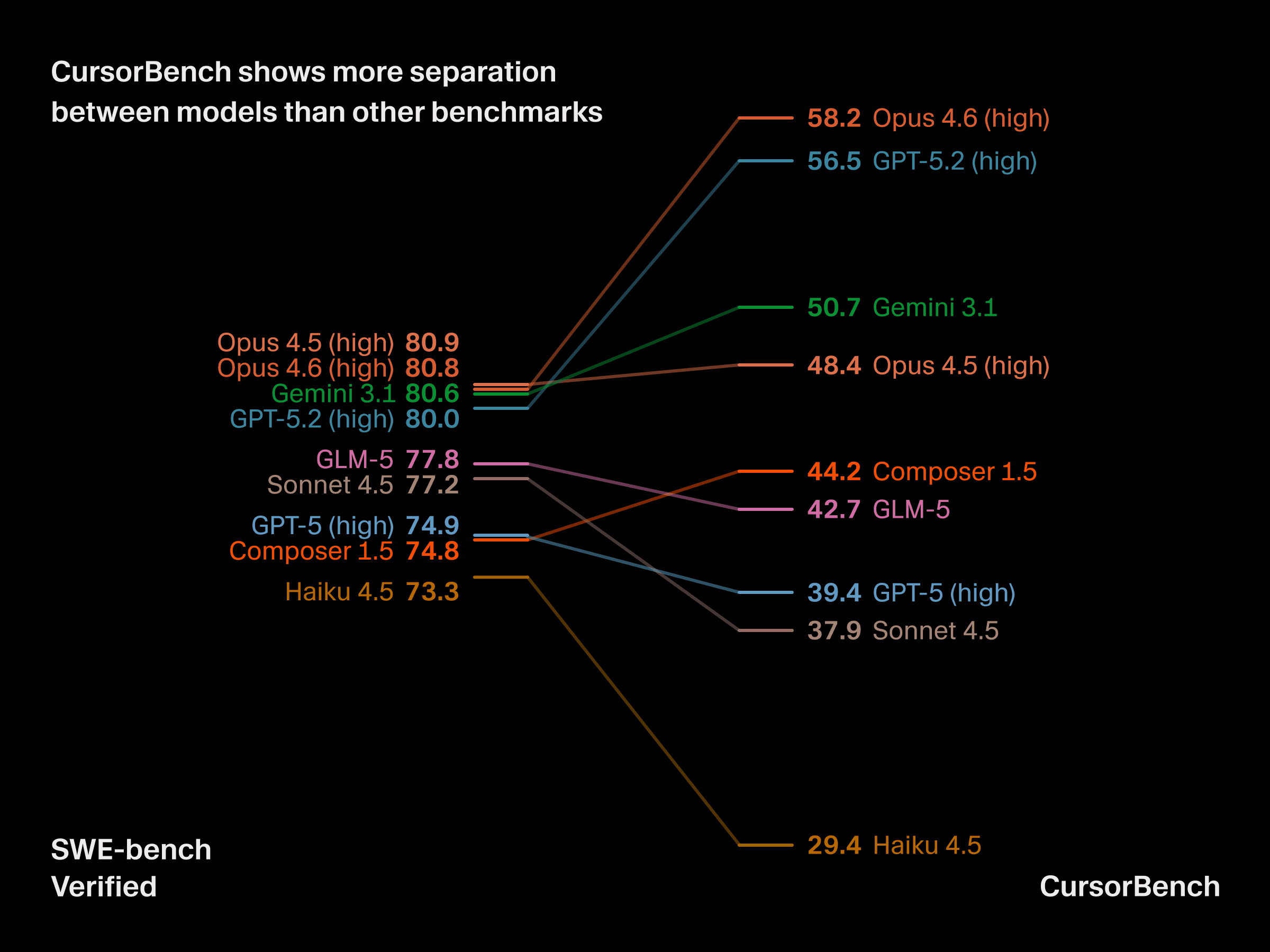
CursorBench 能更好地区分模型
任务复杂度和规格上的这些差异,会直接影响基准测试的实用性。随着公开基准日益趋于饱和,CursorBench 在前沿水平上能更好地区分模型,而且在某些情况下,Haiku 这样的模型可以媲美甚至超过 GPT-5。对于开发者在实际使用中能明显感受到差异的模型,CursorBench 也能稳定地区分开来。

CursorBench 分数与在线评估结果一致
在线评估用于衡量我们对智能体的改进,是否真的能在实际中帮助开发者。我们会跟踪一组反映智能体结果的高层代理指标,其中既包括交互信号,也包括输出质量信号;相比针对某一个指标单独优化,我们更看重这些指标是否都呈现出一致的变化趋势。汇总这些指标后,我们就能发现这类回退:智能体输出在线下评分器中的得分很高,但实际上并不能很好地帮助开发者。
我们通过受控的在线实验来归因影响。例如,在迭代语义搜索与检索时,我们做过一次消融实验,完全移除了语义搜索工具。这样一来,我们就能准确定位语义搜索最关键的场景,例如在较大代码库中基于仓库上下文的问答。
CursorBench 排名也更贴近开发者在 Cursor 中对模型质量的实际体验,这一点可以通过我们的在线评估指标体现出来。


下一代评测套件
虽然 CursorBench-3 的任务比公开基准上的任务持续时间更长,但它们仍然可以在一次会话内完成。我们预计在未来一年里,绝大多数开发工作将转向由在各自计算机上独立运行的长时间运行智能体来完成,因此我们也正规划对 CursorBench 作出相应调整。要做到这一点,我们需要找到降低评测成本的方法,解决与外部服务交互类任务的可复现性问题,并缩小离线评估与开发者体验之间的差距。
在线-离线闭环为我们提供了我们认为正确的基础,我们规划在此基础上继续构建,并在后续分享更多内容。
如果你有兴趣攻克与编程未来相关的深层技术问题,请联系 hiring@cursor.com。